




Рассмотрение модели речевой идентификации, основанной на гласных звуках

Авторы: Добржинская Татьяна Юрьевна, Рогова Олеся Сергеевна, Алентьева Екатерина Романовна
Рубрика: 1. Информатика и кибернетика
Опубликовано в
Дата публикации: 01.02.2019
Статья просмотрена: 36 раз
Библиографическое описание:
Добржинская, Т. Ю. Рассмотрение модели речевой идентификации, основанной на гласных звуках / Т. Ю. Добржинская, О. С. Рогова, Е. Р. Алентьева. — Текст : непосредственный // Актуальные вопросы технических наук : материалы V Междунар. науч. конф. (г. Санкт-Петербург, февраль 2019 г.). — Санкт-Петербург : Свое издательство, 2019. — С. 4-5. — URL: https://moluch.ru/conf/tech/archive/324/14817/ (дата обращения: 30.04.2024).
В данной статье рассмотрена тема об использовании метода распознавания речи как одного их способа идентификации. Речь состоит из двух компонентов — это голосовые и шумовые источники звука. Используя один из компонентов образования речи и была подробно рассмотрена модель речевой идентификации, которая основана на гласных звуках.
Ключевые слова: информационная безопасность, речевая идентификация, модель речевой идентификации.
В нашем мире тяжело представить жизнь без современных технологий. Одна из таких технологий связана с возможностью управлять электронными системами голосом. Крупные компании уделяют внимание данному направлению, так как голос — это уникальный слепок человека, как и отпечатки пальцев. По голосу можно идентифицировать человека, понять его настроение.
Речь как инструмент управления состоит из следующих компонентов: синтез, распознание, понимание. Для того, чтоб понимать речь необходимо грамматические и фонетические знания языка. Анализ синтеза речи основан на модели излучении звуковых волн речевого сигнала.
В речеобразовании существуют голосовые и шумовые источники звуков. Голосовые — основаны на тонах речи при колебании голосовых связок. Такие звуки делятся на гласные и согласные. Гласные звуки построены на частотах основного тона. Шумовые — основаны на дыхании человека (выдох воздуха из лёгких во время разговора).
Построим модель, преимущественно основанную на гласных звуках, где входной сигнал x(t) основан на голосовых связках, проходящий через речевой резонатор N-e и выходящий через речевой сегмент y(t). Из этих условий получаем математическую модель, сумма амплитуд гармоник которой проходит через резонансную систему
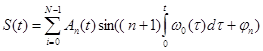
где: n=0, 1, 2… — номер гармоники основного тона;
An — амплитуды гармоник;
w0 — частота основного тона, рад/сек;
jn — начальная фаза гармоник;
S (t) — конечный продукт генеративной и резонансной системы.
Таким образом, имея только выходной сигнал S(t), необходимо рассчитать резонансные и генеративные составляющие.
Для этого необходимо разложить сигнал в квазигармоничный спектр и выбрать в нём составляющую соответствующей частоте тона.
![]() ,
, ![]() ,
,![]() . (1)
. (1)
Проводя сравнение с методами классической оценкой частоты основного тона речи, задача (1) прямо пропорциональна задаче генерации кандидатов искомого периода основного тона, но в отличии от кросскорреляционных подходов тут происходит создание заранее известных функций.
Таким образом TL,N вместе с начальным сигналом SN на входе системы осуществляя выбор функции из основного тона речи. Набор параметров на выходе данной системы, показывающих частоту тона речи в виде Amp — сигнальная амплитуда, F0 — характеристика частоты и T0N — трека функции. Выбор квазигармонической составляющей соответствующей частоте основного тона речи формализуем некоторой функцией выбора:
![]() (2)
(2)
Исходя из этого процесс протекающий в блоке постобработки типовых оценок, в селекторе (2) срабатывает правило решающего отбора идеального кандидата с уточнением последующего значения частоты тона речи.
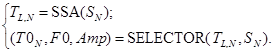 (3)
(3)
Следовательно, соединив (1), (2) модель возможно описать концепции сингулярного оценивания. Тогда, если (3) это производная равенства (1) и определяется решением задачи разложения сингулярного спектрального временного ряда из одномерного в многомерный, то для производной равенства (2) требуется дополнительное рассмотрение.
Используя данную модель, основанную на гласных звуках, можно построить более совершенную модель для речевой идентификации, которая может использоваться в разных областях современной жизни, таких как информационная безопасность, сферы обслуживания, торговли и т. п. Немаловажная особенность и уникальность технологии речевого распознавания и управления это неоценимая помощь людям с ограниченными возможностями.
Литература:
- Вольф Д. А. Построение математической модели селектора сингулярного эстиматора мгновенной частоты основного тона речи // Технические науки — от теории к практике: сб. ст. по матер. XLI междунар. науч.-практ. конф. № 12(37). — Новосибирск: СибАК, 2014.
- Абляев, С. В. Управление человеческими ресурсами на основе компьютерных технологий / С. В. Абляев. — М.: Финансы и статистика, 2006.
- Мельников Защита информации в компьютерных системах / Мельников, Викторович Виталий. — М.: Финансы и статистика; Электроинформ, 2008.
- Соколов, А. В. Защита информации в распределенных корпоративных сетях и системах / А. В. Соколов, В. Ф. Шаньгин. — М.: ДМК Пресс, 2002.
Ключевые слова
Информационная безопасность, речевая идентификация, модель речевой идентификацииПохожие статьи
Построение концептуальной модели сингулярного эстиматора...
Ключевые слова: речь, фонема, модель, сингулярный спектральный анализ речи
Получение концептуальной модели нового класса оценщиков частоты основного тона речи.
Одним из источников образования звуков является голосовой источник, который возникает при...
Модель сингулярного эстиматора частоты основного тона речи
Ключевые слова: речь, фонема, модель, сингулярный спектральный анализ речи, сингулярное оценивание частоты основного тона. Современные информационные технологии находят все более широкое применение в вычислительных и телекоммуникационных системах.
Анализ математических моделей речевого тракта
В целом звуки речи подразделяются на шумы и тоны: тоны в речи возникают в результате колебания голосовых складок; шумы
Рис. 1 Модель речевого сигнала для вокализованного сегмента речи. Известно, что гласные звуки представляют собой квазипериодические...
Базовые принципы построения системы синтеза речи
Синтезом речи называется процесс восстановления формы речевого сигнала по его параметрам.
Именно поэтому первая и наиболее важная задача системы синтеза речи — анализ и
Под просодическими характеристиками подразумевается тон, акцент, ритмика языка.
Выделение границ фонем речевого сигнала с помощью...
В акустико-фонетическом подходе к автоматическому распознаванию речи выделение границ фонем — одна из основных и наиболее сложных
Как видно, метод вычисления скорости измерения спектральных характеристик отобразил границы всех присутствующих звуков в...
Речевые технологии — следующий уровень сервиса
Вторая — система распознавания речи. Распознавание речи — системы, которые
Проблема идентификации пользователя по голосу. На данный момент системы распознания речи
Так же в последнее время речевые технологии популяризовались и в повседневной жизни, быту.
Подходы к выделению речи из исходного сигнала для системы...
Выделение речи из исходного сигнала является важным шагом предварительной обработки речевых сигналов.
речевой сигнал, баз данных, синтез речи, сигнал, основной тон, знак препинания, волна, система синтеза речи, кратковременная энергия, звуковой сигнал.
Исследование формантных частот якутских гласных
Резонансные пики, наблюдающиеся в спектральной картине звуков речи, называются формантами.
Гласные произносятся относительно открытым речевым трактом. Основная акустическая особенность гласных — это местоположение первых трех формантных частот...
Сравнительный анализ методов синтеза речи | Статья в журнале...
В настоящее время представлено большое разнообразие методов синтеза речи. Существуют два основных фактора, от которых зависит выбор технологии синтезирования в конкретной реализации: Задача.
Похожие статьи
Построение концептуальной модели сингулярного эстиматора...
Ключевые слова: речь, фонема, модель, сингулярный спектральный анализ речи
Получение концептуальной модели нового класса оценщиков частоты основного тона речи.
Одним из источников образования звуков является голосовой источник, который возникает при...
Модель сингулярного эстиматора частоты основного тона речи
Ключевые слова: речь, фонема, модель, сингулярный спектральный анализ речи, сингулярное оценивание частоты основного тона. Современные информационные технологии находят все более широкое применение в вычислительных и телекоммуникационных системах.
Анализ математических моделей речевого тракта
В целом звуки речи подразделяются на шумы и тоны: тоны в речи возникают в результате колебания голосовых складок; шумы
Рис. 1 Модель речевого сигнала для вокализованного сегмента речи. Известно, что гласные звуки представляют собой квазипериодические...
Базовые принципы построения системы синтеза речи
Синтезом речи называется процесс восстановления формы речевого сигнала по его параметрам.
Именно поэтому первая и наиболее важная задача системы синтеза речи — анализ и
Под просодическими характеристиками подразумевается тон, акцент, ритмика языка.
Выделение границ фонем речевого сигнала с помощью...
В акустико-фонетическом подходе к автоматическому распознаванию речи выделение границ фонем — одна из основных и наиболее сложных
Как видно, метод вычисления скорости измерения спектральных характеристик отобразил границы всех присутствующих звуков в...
Речевые технологии — следующий уровень сервиса
Вторая — система распознавания речи. Распознавание речи — системы, которые
Проблема идентификации пользователя по голосу. На данный момент системы распознания речи
Так же в последнее время речевые технологии популяризовались и в повседневной жизни, быту.
Подходы к выделению речи из исходного сигнала для системы...
Выделение речи из исходного сигнала является важным шагом предварительной обработки речевых сигналов.
речевой сигнал, баз данных, синтез речи, сигнал, основной тон, знак препинания, волна, система синтеза речи, кратковременная энергия, звуковой сигнал.
Исследование формантных частот якутских гласных
Резонансные пики, наблюдающиеся в спектральной картине звуков речи, называются формантами.
Гласные произносятся относительно открытым речевым трактом. Основная акустическая особенность гласных — это местоположение первых трех формантных частот...
Сравнительный анализ методов синтеза речи | Статья в журнале...
В настоящее время представлено большое разнообразие методов синтеза речи. Существуют два основных фактора, от которых зависит выбор технологии синтезирования в конкретной реализации: Задача.




