





Сегодня нет общего для всех подхода к планированию и внедрению аппаратной виртуализации. В зависимости от того существует ли уже локальная сеть или нет, от масштаба предприятия, необходимо рассчитывать возможные последствия в случае вероятности сбоя, а так же предполагаемые преимущества от внедрения аппаратной виртуализации. Итак, с чего начать организацию миграции на виртуальные сервера? Здесь нелишними будут знания в смежных областях, в частности в области систем хранения данных, потому что при создании кластера серверов данные в кластере размещаются на одном узле, расположенном на внешнем хранилище.
Что представляет собой система хранения данных (далее - СХД)? СХД - это комплексное программно-аппаратное решение по организации надёжного хранения информационных ресурсов и предоставления гарантированного доступа к ним. В случае организации корпоративной СХД следует выделить три архитектуры организации хранения данных:
Direct Attached Storage (далее -DAS);
Network Attach Storage (далее - NAS);
Storage Area Network (далее - SAN).
Устройства DAS (Direct Attached Storage) – решение, когда устройство для хранения данных подключено непосредственно к серверу, или к рабочей станции, как правило, через интерфейс подключения накопителя Fiber Chanel, SCSI, eSATA, SAS.
К основным преимуществам DAS систем можно отнести их низкую стоимость (в сравнении с другими решениями СХД), простоту развертывания и администрирования, а также высокую скорость обмена данными между системой хранения и сервером. Собственно, именно благодаря этому они завоевали большую популярность в сегменте небольших корпоративных сетей. В то же время устройство DAS обеспечивает низкую степень консолидации ресурсов – вся ёмкость доступна одному или двум серверам, т.е. организация обмена пакетами данных происходит напрямую через коммуникационное оборудование, т.е. «точка к кочке».
Устройства NAS (Network Attached Storage) – отдельно стоящая дисковая система, по сути, сервер, со своей специализированной ОС, освобожденной от всех функций, не связанных с обслуживанием файловой системы и реализацией ввода-вывода данных, NAS системы имеют оптимизированную по скорости доступа файловую систему. Устройства NAS проектируются таким способом, что вся их вычислительная мощь фокусируется исключительно на операциях обслуживания и хранения файлов. Таким образом, в сравнении с традиционными файловыми серверами NAS устройства являются более производительными и менее дорогими. В настоящее время практически все NAS устройства ориентированы на использование в сетях Ethernet (Fast Ethernet, Gigabit Ethernet) на основе протоколов TCP/IP. Доступ к устройствам NAS производится с помощью наиболее распространенных протоколов доступа к файлам: CIFS, NFS и DAFS.
CIFS (Common Internet File System— общая файловая система Интернет) - протокол, который обеспечивает доступ к файлам и сервисам на удаленных компьютерах и использует клиент-серверную модель взаимодействия. Для транспортировки данных CIFS использует TCP/IP протокол. CIFS позволяет разделять доступ к файлам между клиентами, используя блокирование и автоматическое восстановление связи с сервером в случае сбоя сети.
NFS (Network File System - сетевая файловая система) применяется на платформах UNIX и представляет собой совокупность распределенной файловой системы и сетевого протокола. Протокол NFS обеспечивает доступ к файлам на сервере так, как если бы они находились на клиенте. Для транспортировки данных NFS использует протокол TCP/IP.
DAFS (Direct Access File System — прямой доступ к файловой системе) — это протокол файлового доступа, который основан на NFS. Данный протокол позволяет прикладным задачам передавать данные в обход операционной системы и ее буферного пространства напрямую к транспортным ресурсам. DAFS проектировался с ориентацией на использование в кластерном окружении для баз данных и web-приложений, ориентированных на непрерывную работу. Протокол поддерживает механизмы восстановления работоспособности системы и данных, что делает его привлекательным для использования в NAS системах.
Резюмируя вышеизложенное, NAS системы можно рекомендовать для использования в гетерогенных сетях среднего размера.
Устройства SAN (Storage Area Network) – это программно-аппаратный комплекс, организовывающий выделенную сеть, интегрированную в LAN (или WAN), объединяющий устройства хранения данных с серверами приложений, строится на основе протоколов Fiber Channel, iSCSI, SAS. При этом важно, что трафик внутри SAN сети отделен от IP трафика LAN, что позволяет снизить загрузку локальной сети. Концепция построения топологии сети хранения данных базируется на тех же принципах, что и традиционные локальные сети на основе коммутаторов и маршрутизаторов, коммутационные фабрики Fiber Channel с неблокирующей архитектурой позволяют реализовать одновременный доступ множества серверов к устройствам хранения данных. К преимуществам технологии SAN можно отнести высокую производительность, высокий уровень доступности данных, отличную масштабируемость и управляемость, возможность консолидации и виртуализации данных, т.к. в отличие от NAS, SAN не имеет понятия о файлах: файловые операции выполняются на подключенных к сети SAN серверах. Следует отметить, что процесс консолидации данных невозможен в случае использования других технологий, как, например, при применении DAS устройств, то есть СХД, непосредственно подсоединяемых к серверам.
Практически единственным недостатком SAN на сегодня остается относительно высокая цена компонент, но при этом общая стоимость владения для корпоративных систем, построенных с использованием технологии СХД, является довольно низкой.
Одним их важнейших этапов реорганизации корпоративной сети (далее - КС) является этап расчёта показателей надёжности её функционирования, причём хорошее качество проектирования избавляет от дополнительных материальных и временных затрат на устранение ошибок на стадии эксплуатации. С усложнением программно-аппаратных комплексов, применяемых для реализации конкретной КС, возникает необходимость в оценке показателей надёжности и эффективности таких систем. На сегодняшний момент наиболее эффективными при анализе надёжности являются абстрактные модели, построенные не на основе конкретных аппаратных единиц, а на базе логических подсистем, реализующих конкретные функции в работе сети. На первом этапе проектирования данные модели позволяют определить оптимальную надёжность логических подсистем. Но на последующих этапах проектирования для перехода от абстрактных функциональных блоков в модели надёжности к более конкретным подсистемам, которые могут быть доведены до программно-аппаратной реализации.
Рассмотрим вероятность того, что система, находясь в момент времени t0 = 0 в момент времени t окажется в нерабочем состоянии, т.е. откажет. Вероятность отказа здесь обозначим через Q0. Будем считать, что &#;(t) – функция распределения времени восстановления i-го элемента; &#;(t) = 1 – exp{– &#;it} – функция распределения времени работы до отказа i-го элемента. Поведение системы можно описать некоторым случайным процессом &#;(t). Пространство состояний этого процесса E = {0, 1, 2, …} [1]. Предположим, что в начальный момент времени &#;(0) = 0, т.е. в системе все элементы находятся в работоспособном состоянии. Переход из некоторого состояния n – l в состояние n – l + 1 следует рассматривать как отказ одного элемента. В зависимости от того, сколько элементов должны оставаться работоспособными, чтобы вся система находилась в работоспособном состоянии, под отказом системы можно понимать переход:
- из состояния n – 1 в состояние n, если для работоспособного состояния системы достаточно, чтобы один элемент находился в рабочем состоянии;
- из некоторого состояния n – m в состояние n – m + 1, если система остаётся работоспособной при m работающих элементах.
В частности второму варианту соответствует условие работоспособности центра обработки данных оператора связи, где для нормального функционирования системы, достаточно, чтобы из 1000 серверов работало примерно 950. Преимущество описанной выше схемы заключается в том, что она позволяет легко выделить промежуточные состояния, например, состояние частичного отказа. Оценим характеристики надёжности для данной модели. Время до первого отказа системы оценивается как: t = min{t: z(t) = n | z(0) = 0} [1]. На рис. 1 показаны графики результатов имитационного моделирования системы, состоящей из 50 элементов. Для наглядности элементы считались одинаковыми и под отказом понимался: 1) отказ 40 элементов (отказ в момент τ1), 2) отказ 30 элементов (момент τ2). Из траекторий реализации случайного процесса видно, что оценки времени работы системы до первого отказа и вероятности отказа по монотонной траектории могут быть использованы в качестве нижних границ надёжности.
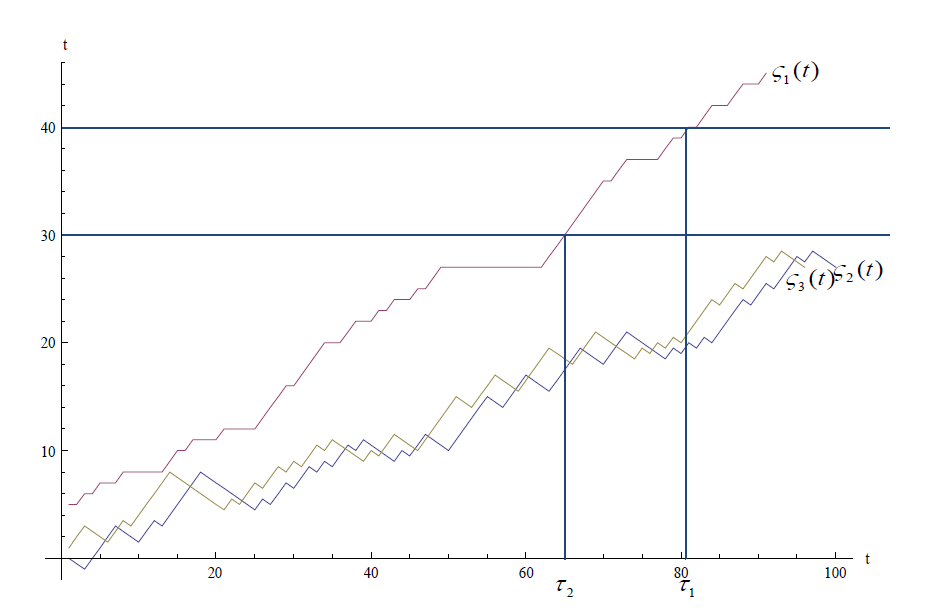
Рис. 1. График траектории случайного процесса
Рассчитывая надёжность корпоративной сети в процессе перехода на виртуальные сервера, восстанавливаемые в процессе эксплуатации и работающие параллельно в смысле надёжности, всегда надо учитывать возможность как аппаратного, так и программного сбоя. При этом если на кластере организовывается несколько виртуальных машин, то надежность повысится, т.к. в случае аппаратного сбоя на сервере его роли примут на себя другие сервера кластера, а в случае программного сбоя гостевой ОС время восстановления будет значительно меньшим.
Большинство «mission critical» приложений не являются кроссплатформенными, разрабатываются для работы под управлением OC Windows и развертываются на «родительских» ОС, т.к. существует распространенное мнение, что нет возможности выделить серверной гостевой ОС под управлением Windows более восьми виртуальных процессорных устройств. Сравнивая возможности актуальных на данный момент гипервизоров, следует отметить важное нововведение на базе гипервизора VMware. Технология VMware multicore virtual CPU позволяет управлять количеством ядер в виртуальных CPU, один виртуальный процессор может иметь несколько ядер. Эта возможность позволяет операционным системам использовать больше ядер CPU, что повышает общую производительность виртуального сервера.
Последняя из сложностей при внедрении виртуализации заключается в том, что далеко не всегда специалисты в области информационных технологий знакомы с областью аппаратной виртуализации, а высший менеджмент, одобряющий затраты на внедрение этой технологии, требует стабильного функционирования критичных приложений. Но не только это требование является резонным желанием руководства, привыкшего объясняться на языке презентаций и отчетов, желание знать какие затраты понесет предприятие и какую прибыль это даст - вот основное требование, вследствие которого затраты на ИТ-бюджет неизменно оптимизируются «по полной» Все, в конце концов, сводится к тому, чтобы воспользоваться экономическими выгодами от виртуализации, при этом, получая более гибкую и подвижную инфраструктуру. Если инфраструктура ЛВС уже отлажена и работает стабильно, то ИТ-специалист сталкивается с вопросом руководства «Зачем нам это надо?», «Будут ли виртуальные сервера работать так же надежно, как и физически существующие?» и главная задача ИТ-специалиста - рассчитать и обосновать, что надежность и эффективность системы возрастают и затраты окупаются.
- Литература:
Воронцов Ю.А. Обеспечение надежности корпоративных сетей операторов связи / Ю.А. Воронцов, Э.Ю. Калимулина: Вестник связи. – 2004. – №10.4.
Лукьянов В.С. Модели топологических структур проводных телекоммуникационных сетей: монография / В.С. Лукьянов, Д.Г. Владнев, А.В. Старовойтов; ВолгГТУ - Волгоград, 2006. – 176с.
Перегуда А. И. Математическая модель надёжности информационных систем / А. И. Перегуда, Р.Е. Твердохлебов: Методы менеджмента качества. – 2004. – №6.
Черкесов Г. Н. Надёжность аппаратно-программных комплексов. – Спб.: Питер, 2005.
- Russia.emc.com: официальный сайт компании EMC2 [Электронный ресурс]. – Режим доступа: http://russia.emc.com/, свободный. – Загл. с экрана.
- Netapp.com: официальный сайт компании Netapp [Электронный ресурс]. – Режим доступа: http://www.netapp.com/ru/, свободный. – Загл. с экрана.
- Vmware.com: официальный сайт компании VMware [Электронный ресурс]. – Режим доступа: http://www.vmware.com/ru/, свободный. – Загл. с экрана.
