





В статье описывается модифицированная версия алгоритма Round-Robin, применяемая в задаче параллельного экспорта файлов внутри распределенной системы хранения данных.
Ключевые слова: параллельный экспорт файлов, Round-Robin, распределенная система хранения данных.
Постановка задачи: есть распределенная система хранения данных, которая, помимо хранения, может экспортировать файлы с одного на N узлов. Необходимо оптимизировать процесс передачи файлов, а именно, минимизировать время простоя узла- источника.
Базовый алгоритм «ROUND_ROBIN» заключается в следующем: на вход исходному узлу (далее SRC_NODE) приходит множество файлов. Он разбивает их на пачки определенного размера, и передает на N конечных узлов (далее i-й конечный узел будем называть DEST_NODE_i).
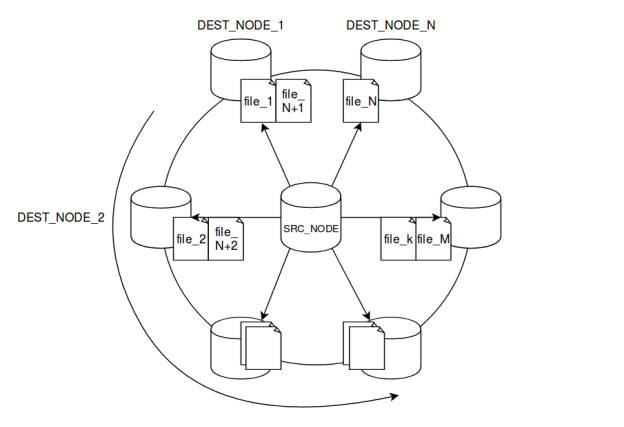
Рис. 1. Схема распределения файлов по алгоритму ROUND_ROBIN
Пачка распределяется равномерно, по алгоритму ROUND_ROBIN — по кругу каждый файл назначается на свой DEST_NODE. Если количество DEST_NODE'ов меньше числа файлов, то после того как было распределено N файлов, DEST_NODE'ы начинаются сначала, то есть, N+1 файл уйдёт на DEST_NODE_1 и так далее. До тех пор, пока экспорт всех файлов не завершится, SRC_NODE простаивает в ожидании, так как должен получить ответ от всех N DEST_NODE'ов.
Минус базового алгоритма: DEST_NODE'ы могут располагаться на разных по мощности машинах, и в случае если один из них будет слишком долго принимать файлы, или, того хуже, зависнет, вызывающая сторона очень долго не сможет узнать об этом.
Решение
В качестве решения была выбрана модификация — «взвешенный ROUND_ROBIN». Суть алгоритма заключается в присвоении каждому из DEST_NODE'ов некоторой оценки качества его работы. Оценка качества проводится с периодом T. За это время, собирается статистика работы принимающих узлов: как быстро и успешно ли прошёл экспорт, какой из узлов отказался принимать файл и так далее.
Во время T происходит обработка полученной статистики, и на её основе, с помощью описанных далее метрик, определяется значение «веса» того или иного узла. Чем выше вес — тем больше файлов будет экспортировано на этот узел, и наоборот. Это сделано с целью уменьшить среднее по узлам время, затрачиваемое на экспорт, что, соответственно, уменьшает время простаивания SRC_NODE'а.
Помимо этого, измерение веса одного узла относительно других позволяет сделать вывод об его эффективности. В случае, если один из узлов показывает очень плохие результаты и сильно тормозит общий экспорт, он автоматически отключается, и далее экспорт будет происходить на оставшиеся N-1 узлов.
Алгоритм изменения веса
На каждом этапе изменения веса предполагается, что следующий вес никоим образом не зависит от предыдущих, а новый высчитывается лишь исходя из собранной за текущий период Tk статистики по узлам.
Введём следующие обозначения:
N — текущее количество узлов, на которые происходит экспорт
ti = {ti1, ti2, …, tiki} — множество значений времени экспорта на узел i файлов в количестве ki, i = 1,…,N.
Тогда можем посчитать toi = ti1 + ti2 + … + tiki — суммарное время, затраченное на экспорт на i-тый DEST_NODE.
Теперь можем посчитать среднее время экспорта среди всех узлов, как:
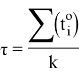
k = k1 + k2 + … + kN — количество успешно отправленных файлов. Величина τ понадобится нам в дальнейшем.
Также нам понадобится средняя скорость передачи файлов:
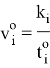
Наконец, вычислим новое значение для желаемого количества передаваемых узлов файлов, как:
![]()
здесь полускобки — взятие числа без остатка.
Данные веса ![]() , i=1,…,N подошли бы нам в случае, если бы число экспортируемых файлов было равно число экспортированных файлов за предыдущий период T. Наша же задача — сделать оптимальный экспорт каждой из пачек файлов. Так что полученные значения необходимо нормализовать.
, i=1,…,N подошли бы нам в случае, если бы число экспортируемых файлов было равно число экспортированных файлов за предыдущий период T. Наша же задача — сделать оптимальный экспорт каждой из пачек файлов. Так что полученные значения необходимо нормализовать.
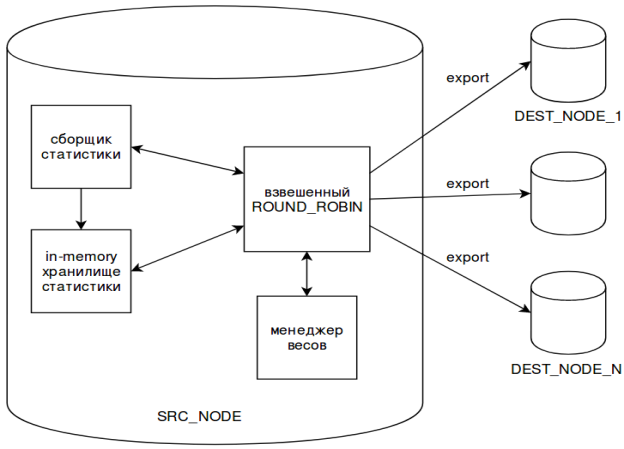
Рис. 2. Архитектура программной реализации алгоритма
Будем считать, что число файлов p в каждой из пачек примерно одинаково и равно усредненному значению между пачками за предыдущий период, о чем мы тоже знаем из собранной статистики.
Тогда можем сделать вывод, что в каждой пачке должно быть количество файлов, равное:
где C — фиксированный коэффициент. При нормировании он будет равен:
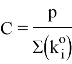
Тогда новые, нормированные веса будут равны:
![]()
На рисунке 2 можно увидеть архитектуру модулей, необходимых при реализации данного решения.
Литература:
- Соболева О. Н. и др. Разработка приложения для балансировки нагрузки на комплексе серверов виртуальных машин: магистерская диссертация по направлению подготовки: 02.04. 02-Фундаментальная информатика и информационные технологии. — 2016.
- https://en.wikipedia.org/wiki/Round-robin_scheduling
- https://en.wikipedia.org/wiki/Weighted_round_robin
