





Recurrent Neural Networks encoder and decoder systems for text summarization have been achieved high scores on short input or output texts. But for a long texts these systems often produce not coherent phrases, which often repeat themselves. In this paper I present my approach to this problem by solution based on deep learning model and a training method that combines supervised learning for word prediction, as well as reinforcement learning. I evaluate this model on the modified CNN dataset. My model obtains a 43.31 ROUGE 1-gram metric on the CNN dataset.
1. Introduction
Text summarization is very important task in Natural Language Processing, since it compresses text, and this compressed text we can use for whole range of other purposes. Two main approaches for text summarization solution are: 1) with the use of copying certain parts of the input text; 2) generation of new sentences, which could come as rephrasing or using words which are different then that from the input text.
Deep learning systems which are based on an attentional encoder and decoder models for machine translation are able to generate text summaries with high ROUGE metric. The negative side of this approach is that it is usable only on very short texts (usually 1 or 2 sentences long). With using much longer input text, scientists receive bad result which is usually output text with unnatural for human understanding summary, which also contains repeating phrases.
I this paper I present a new text summarization system that gives high result on the modified CNN dataset. I will describe my key attention mechanism, and to get rid of the repeating phrases I will use an intra-temporal attention in the encoder component which memorizes prior attention weights for each of input tokens, as well as using a sequential intra-attention sub-system in the decoder component, which cleans the output by considering the words which have been already generated by the decoder.
2. Intra-attention model, based on neural networks
My intra-attention model, based on the encoder and decoder net, is represented here:
Definition: token — is a word; or sequence of symbols, surrounded by spaces.
1) x — is a sequence of input text tokens (expression 1):
2) y — sequence of output text tokens (expression 2):
![]() (2)
(2)
My model reads the input text tokens using a two directional Long Short Term Memory (LSTM) encoder, while computing hidden states from the word vectors of x.
I use one component of LSTM decoder to create hidden states from word vectors of y.
On every decoding step t, — algorithm uses an intra-temporal attention function in order to attend over certain parts of the input sequence, which was previously encoded, as well as to the decoder’s own hidden state and the word which was previously generated. This type of attention deters the model from attending over the recurring parts of the input text on different decoding steps. Such an intra-temporal attention may decrease the amount of repetitions when attending over input texts of large size.
Let's symbolize as attention score eti of the hidden input state hei which is at decoding of time step t as (formula 3):
(3) ![]()
where f is defined by following (formula 4):
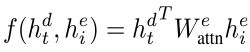 (4)
(4)
I normalize the attention scores with the following temporal attention function. I define new temporal scores by next formula 5:
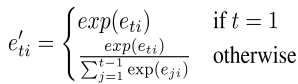 (5)
(5)
Then I compute the normalized attention scores (formula 6):
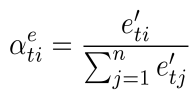 (6)
(6)
and then compute input context vectors (formula 7):
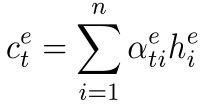 (7)
(7)
I incorporate more information about the sequence, which was prior to that decoded, into the decoder. The possibility of looking back at previous decoding steps will allow my model to make more structured predictions and to deter repetition of the same information. I introduce an intra-decoder attention mechanism, which is usually not present in existing encoder-decoder models for text summarization.
On every decoding step t my model computes a new decoder context vector (formula 8):
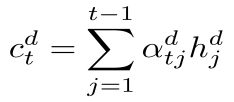 (8)
(8)
To generate a token, — my decoder can use a pointer mechanism to copy rare or unseen from the input sequence, or a token-generation softmax layer. I use a switch function which calculates for every decoding step whether to use the pointer or the token generation. I define ut as a binary value, equal to 1 if the pointer mechanism is used to make an output of yt, and 0 in the other cases. My token-generation layer generates the following probability distribution function (9):
![]() (9)
(9)
The following matrix is for token generation layer:
3. Learning objective
Now let's explore ways of training our encoder-decoder model. In particular, I will propose reinforcement learning-based algorithms with their application to text summarization task.
Symbolize with y* (formula 11) — the optimal output for given input x.
(11)![]()
My algorithm's objective is to minimize the following loss function (formula 12):
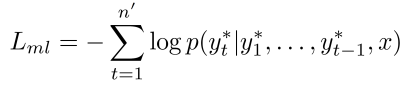 (12)
(12)
But it's better to optimize another metric, since the formula 12 does not always guarantee optimal results. For this purpose in reinforcement learning we can define function r(y) to be a reward function of output y.
So now our goal is to minimize the function (formula 13):
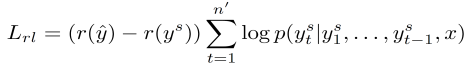 (13)
(13)
But both of the formulas 12 and 13 has their advantages and disadvantages, so as a result I define a mixed learning objective function which combines equations 12 and 13 (formula 14):
5. CNN dataset
I evaluate my model on modified version of CNN dataset. This dataset contains more than 287000 training samples, and more than 13000 validation samples and about 11500 testing samples.
6. Results
|
Model |
ROUGE-1 |
|
Reinforcement Learning (using intra-attention) |
43.31 |
|
Machine Learning (using intra-attention) |
39.42 |
|
Machine Learning (no intra-attention) |
38.98 |
|
Machine Learning & Reinforcement Learning (using intra-attention) |
40.96 |
7. Conclusion
In this paper I presented a new model and training function that obtains high results in text summarization task for the CNN news corpus, improves the human readability of the generated output texts (summaries) and is better suited for a long text outputs.
My intra-attention decoder and combined training objective — could be applied for wide range of problems, for which there is a long sequence-to-sequence of inputs and outputs, which I will try to cover in my further research.
References:
- Ramesh Nallapati, Feifei Zhai, and Bowen Zhou. Summarunner: A recurrent neural network based sequence model for extractive summarization of documents. Proceedings of the 31st AAAI conference, 2017.
- Hakan Inan, Khashayar Khosravi, and Richard Socher. Tying word vectors and word classifiers: A loss framework for language modeling. Proceedings of the International Conference on Learning Representations, 2017.
- Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. Proceedings of the International Conference on Learning Representations, 2017.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pp. 3111–3119, 2013.
- Qian Chen, Xiaodan Zhu, Zhenhua Ling, Si Wei, and Hui Jiang. Distraction-based neural networks for modeling documents. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), pp. 2754–2760, 2016.
- Jianpeng Cheng, Li Dong, and Mirella Lapata. Long short-term memory-networks for machine reading. arXiv preprint arXiv:1601.06733, 2016.
- Sumit Chopra, Michael Auli, Alexander M Rush, and SEAS Harvard. Abstractive sentence summarization with attentive recurrent neural networks. Proceedings of NAACL-HLT16, pp. 93–98, 2016.
- Caglar Gulcehre, Sungjin Ahn, Ramesh Nallapati, Bowen Zhou, and Yoshua Bengio. Pointing the unknown words. arXiv preprint arXiv:1603.08148, 2016.
- Sepp Hochreiter and J¨urgen Schmidhuber. Long short-term memory. Neural computation, 9(8): 1735–1780, 1997.
- Kai Hong and Ani Nenkova. Improving the estimation of word importance for news multi-document summarization-extended technical report. 2014.
- Kai Hong, Mitchell Marcus, and Ani Nenkova. System combination for multi-document summarization. In EMNLP, pp. 107–117, 2015.
- Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. In Advances in Neural Information Processing Systems, pp. 1693–1701, 2015.
- Mohammad Norouzi, Samy Bengio, Navdeep Jaitly, Mike Schuster, YonghuiWu, Dale Schuurmans, et al. Reward augmented maximum likelihood for neural structured prediction. In Advances In Neural Information Processing Systems, pp. 1723–1731, 2016.
- Benjamin Nye and Ani Nenkova. Identification and characterization of newsworthy verbs in world news. In HLT-NAACL, pp. 1440–1445, 2015.
- Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. In EMNLP, volume 14, pp. 1532–1543, 2014.
- Ronald J Williams and David Zipser. A learning algorithm for continually running fully recurrent neural networks. Neural computation, 1(2):270–280, 1989.
- Ofir Press and Lior Wolf. Using the output embedding to improve language models. arXiv preprint arXiv:1608.05859, 2016.
- Ronald JWilliams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8(3–4):229–256, 1992.
