





The study has reviewed some trends of the digital world that include scalability of infrastructure, integration of services and flexibility of internal management that make a great impact on commercial centers and public places were reviewed. The importance of solving of indoor positioning problem by means of video surveillance systems integrator and customer smartphones applications was demonstrated. It was mentioned that automation of the customer positioning procedure has to be performed by means of the artificial neural network which will ensure reducing the amount of “person-to-machine” interactions. It was proposed to implement region-based convolutional neural networks for object recognition algorithm. Training of the conventional R-CNN model was proved to be the resource-intensive and time-consuming process, which implies running selective search procedure to thousands of regions of interest for every image and estimation of the feature vector for every region. Therefore it was considered to use Fast R-CNN model which unifies convolutional neural network, support vector machine and regression model into one trained framework. Modifications of this model (Faster R CNN and Mask R-CNN) show high performance and can be used for indoor positioning image recognition task.
Keywords: indoor positioning, video surveillance systems integrator, artificial neural network, R CNN, a loss function, intersection over union, region of interest or ROI.
1. Introduction
Nowadays shopping centres and public places tend to grow up, integrate various services with the frequent reorganization of the whole system. Shopping malls could be integrated with entertainment complexes, restaurants, etc. Lately, it also became typical for airport terminals or railway station buildings. Those factors together could be labelled as digital world trends (Figure 1):
‒ scalability of infrastructure;
‒ integration of services;
‒ flexibility of internal management.
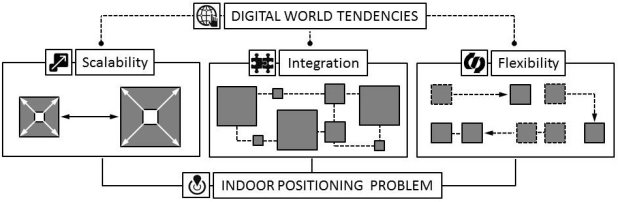
Fig. 1. Digital world tendencies impact on commercial centres and public places organization.
Digital era organizing methodology can significantly increase the standard of living and save customers time, but it also has obvious weaknesses. In the digital world, it is easy to smooth over inconveniences caused by system scaling and reorganization by automatic updating of the links but in the real world it usually tends to great deal of confusion. Thereby it is very important to solve indoor positioning problem by erasing boundaries between digital and real world via the augmented reality (AR) tools. Video surveillance systems integrator and customer smartphones applications can be organized on the base of a shopping centre. Generally, there are two strategies which have to be combined. Regarding the reactive strategy, the data from customer’s mobile device camera has to be analysed and used to help customer with indoor positioning, while proactive strategy implies the analysis of the data from video surveillance systems that identify the customer and propose via the mobile device advertising services to his current location. It is obvious that combining of both strategies will help to solve indoor positioning problems more precisely and organize advertising services to the customer with minimum violation of privacy. Automation of the customer and place positioning procedure has to be provided by means of the artificial neural network (ANN) that will enable reducing the volume of “person-to-machine” (P2M) interactions and, thereby, decreasing the number of staff involved in the routine activity (Figure 2).
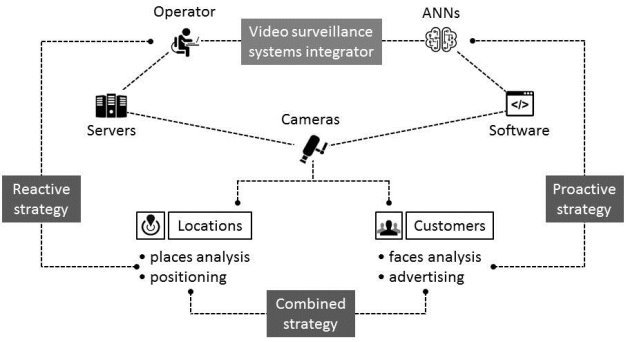
Fig. 2. Indoor positioning method based on the video surveillance systems integrator and ANN.
The assigned task could be solved by object recognition algorithms based on the convolutional neural network (CNN) models [1–3]. In order to identify the main aspects of the problem, the analysis of modern studies was performed. The aspects of the development of region-based convolutional neural networks [4–11] were reviewed, specifically fast R-CNN [6, 7], faster R-CNN [8–9] and mask R CNN [6, 9–11]. Finally the YOLO model (“You Only Look Once” algorithms) that treats the object recognition task as a unified regression problem was studied [12], and proved to be different from the R-CNN models family and resource-intensive, but still quite efficient model.
The systematic analysis shows the possibility to develop the effective technique of indoor positioning for commercial centres and public places based on monitoring and gathering of information from video surveillance systems integrator and customer smartphones with further analysis by R-CNN family ANNs models.
2. Region-based convolutional neural networks object recognition algorithm
R-CNN models family is based on the class of deep, feed-forward ANNs (FFNN) known as convolutional neural network (CNN). CNN is commonly applied to visual object recognition [1‑3]. Development of CNNs models family includes implementation of the multilayer perceptrons with minimal pre-processing. The CNN work algorithm is similar to biological connectivity pattern between neurons of human brain visual cortex where neurons respond in a restricted region of the visual field (receptive field). While receptive fields of neurons are partially overlapped together they could cover the entire visual field. CNNs proved to be highly efficient ANNs models class while they use minimal pre-processing time in comparison with other image processing ANN algorithms.
A key aspect of CNN implementation procedure is the analysis of the input image by several layers [1–3]. To increase the accuracy of the CNN work, the samples of each layer should have partial overlapping. The CNN input layer matrix of weight coefficients (convolution core) is to be used for neurons. The layer obtained as a result of the convolution procedure highlights the characteristics of the image and, thereby forms a feature map for the processing layer. During the subsampling stage, the dimension of the obtained feature cards has to be reduced. It enables accelerating further calculations and getting the invariance of CNN with respect to the scale of the input image. Further, the signal passes through the convolution layers, where the convolution and subsampling operations are repeated, and on each next layer the features of the map decrease, and the number of channels, on the contrary, increases (Figure 3).
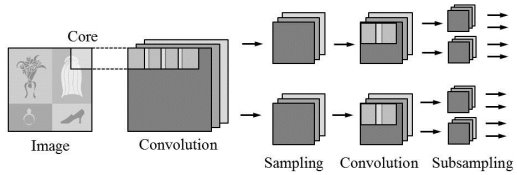
Fig. 3. Operation algorithm of convolutional neural network model.
On the other hand, R-CNN algorithm includes selective search, which enables to identify a manageable number regions of interest (RoI) as of bounding-box object region candidates and extracts CNN features from each region independently for classification (Figure 4). Thereby, the whole cycle includes further stages [4, 5]:
‒ pre-train of the CNN on image classification tasks, which involves ![]() classes;
classes;
‒ estimation by the selective search of the category-independent and different size RoI, which contain target objects;
‒ unification of RoI’s size to the required by CNN parameters through distortion procedure (warping);
‒ determination of the RoI class that refers to the background and includes no object of interest;
‒ fine-tuning the CNN on distorted RoI for ![]() classes;
classes;
‒ implementation of all RoI forward propagation procedure and estimation of the feature vector which has to be consumed by a binary support vector machine (SVM);
‒ training of regression model to correct the predicted detection window on bounding box correction offset using CNN features to reduce the localization errors.
It should be noticed that SVM has to be trained for each class. The positive samples up to the scheme are determined as proposed regions, which intersection over union (IoU) parameter is higher than the threshold value![]() .
.

Fig. 4. The architecture of R-CNN models family
Training of the conventional R-CNN model is a resource-intensive and time-consuming process while it implies running selective search procedure to thousands of RoI for each image and estimation of feature vector for every region. While the discussed procedure involves three models (CNN that classifies image and extracts features, SVM classifier that identifies target objects, regression model that should be used for RoI tightening) which are meant to be computed separately, it is easy to propose more effective R-CNN architecture, which would include the shared computation.
3. Fast region-based convolutional neural networks object recognition algorithm
Fast R-CNN is a model from R-CNN family which unifies CNN, SVM and regression model into one trained framework [6, 7]. The model of framework implies CNN forward pass over the entire image and thus RoI shares this feature matrix which could be branched out for learning the object classifier and the regression model (Figure 5).
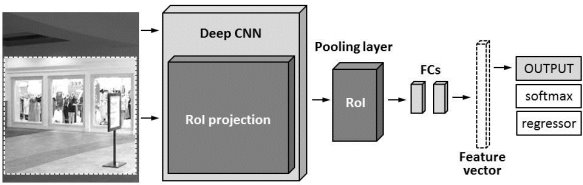
Fig. 5. The architecture of Fast R-CNN model
As it is shown in Figure 5, determination of RoI pooling layer is an important stage of the Fast R‑CNN algorithm implementation. RoI pooling layer is a type of max pooling to convert features in the region of the image of size ![]() to the fixed size window
to the fixed size window![]() . Thereby, the region has to be divided to
. Thereby, the region has to be divided to ![]() grids, where every subwindow will get the size of
grids, where every subwindow will get the size of ![]() with further implementation of max-pooling.
with further implementation of max-pooling.
Development of basic model of Fast R-CNN includes further steps:
‒ pre-train of CNN on image classification tasks;
‒ estimation by the selective search of the RoI (usually 2000 regions per image);
‒ altering the pre-trained CNN by replacing the last max pooling layer with a RoI pooling layer which outputs feature vectors as a sharing computation procedure;
‒ altering of the pre-trained CNN by replacing of the last fully connected layer (FC) and the last softmax function (normalized exponential function) for the layer ![]() with a FC and softmax of
with a FC and softmax of ![]() background class;
background class;
‒ softmax estimation of the ![]() class with getting a discrete probability distribution function value for every RoI;
class with getting a discrete probability distribution function value for every RoI;
‒ Prediction of relative to the original RoI offsets for each class of ![]() classes using the regression model.
classes using the regression model.
For the description of the Fast R-CNN model in the mathematical form, it is necessary to estimate further variables and functions:
‒ true class label ![]() ;
;
‒ RoI discrete probability distribution ![]() which can be computed by a softmax function;
which can be computed by a softmax function;
‒ true bounding box function ![]() ;
;
‒ predicted bounding box correction function ![]() .
.
The loss function ![]() consists of the classification loss function
consists of the classification loss function ![]() and bounding box prediction loss function
and bounding box prediction loss function![]() . It should be noted, that for the background set of the RoI bounding, box prediction loss function has to be neglected and thereby
. It should be noted, that for the background set of the RoI bounding, box prediction loss function has to be neglected and thereby ![]() is to be used:
is to be used:
 , (1)
, (1)
where classification loss function can be estimated:
![]() (2)
(2)
and bounding box prediction loss function states:
![]() .(3)
.(3)
![]() .(4)
.(4)
Integration of the RoI proposal algorithm with the CNN enables building Faster R‑CNN composed of region proposal network (RPN) and fast R-CNN [8, 9]. Development of Faster R‑CNN includes further steps:
‒ pre-train of the CNN on image classification tasks;
‒ RPN fine-tuning initialized by the pre-train image classifier;
‒ estimation of positive samples IoU threshold value as ![]() (
(![]() >0.7) and negative IoU threshold value as
>0.7) and negative IoU threshold value as ![]() (
(![]() >0.3);
>0.3);
‒ sliding spatial window over the image feature map;
‒ predicting multiple regions centre of each sliding window simultaneously;
‒ training of the Fast R-CNN model on the current RPN proposals;
‒ initializing of RPN training by the Fast R-CNN network;
‒ fine-tuning of the Fast R-CNN unique layers.
For the description of the Faster R-CNN model in the mathematical form, it is necessary to estimate further variables and functions:
‒ ![]() as predicted probability that anchor
as predicted probability that anchor ![]() is an object;
is an object;
‒ ![]() as round truth label that anchor
as round truth label that anchor ![]() is an object;
is an object;
‒ ![]() as predicted parameterized coordinates set;
as predicted parameterized coordinates set;
‒ ![]() as ground truth coordinates;
as ground truth coordinates; ![]() as mini-batch size;
as mini-batch size;
‒ ![]() as a number of anchor locations.
as a number of anchor locations.
Thereby equation (1) for the Faster R-CNN model can be set as:
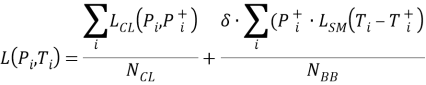 ,(5)
,(5)
where ![]() is balancing parameter that enables getting
is balancing parameter that enables getting ![]() and
and ![]() equally weighted. The
equally weighted. The ![]() function can be obtained as:
function can be obtained as:
![]() .(6)
.(6)
Mask R-CNN has to be considered as Faster R-CNN with pixel-level image segmentation, which includes decoupling of the classification process and the pixel-level mask prediction [9–11]. The mask prediction module could be built as a network applied to all RoI which enables predicting pixels of the segmentation mask. The pixel-level segmentation requires a high level of the fine-grained alignment RoI pooling layer should be improved for precise mapping of the input image regions.
Loss function of Mask R-CNN includes the loss of classification, localization and segmentation mask function
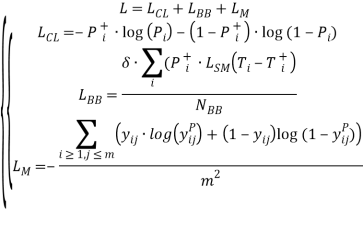 ,(7)
,(7)
where ![]() is a ground truth class,
is a ground truth class, ![]() is the label of a cell
is the label of a cell ![]() in the region of
in the region of ![]() size and
size and ![]() is the predicted value.
is the predicted value.
Mask R-CNN shows high performance and enables developing effective indoor positioning system based on video surveillance systems integrator and customer mobile devices.
4. Conclusions
Region-based convolutional neural networks were proposed for object recognition algorithm at an indoor positioning system. It was shown that training of the conventional R-CNN model is extremely resource-intensive and time-consuming process while it implies running selective search procedure to thousands of regions of interest for every image and also the estimation of the feature vector for every region. Therefore it was proposed to use Fast R-CNN model, which unifies convolutional neural network, support vector machine and regression model into one trained framework. The systematic analysis of recent studies has shown that modifications of this model such as Faster R‑CNN and Mask R‑CNN demonstrate high performance and can be used for indoor positioning image recognition task.
References:
- Sercu, T., & Goel, V. (2016). Advances in Very Deep Convolutional Neural Networks for LVCSR. Interspeech 2016. doi:10.21437/interspeech.2016–1033
- Shinohara, Y. (2016). Adversarial Multi-Task Learning of Deep Neural Networks for Robust Speech Recognition. Interspeech 2016.
- Venkatesan, R., & Li, B. (2018). Convolutional neural networks in visual computing: A concise guide. Boca Raton, FL: CRC Press.
- Adam, B., Zaman, F., Yassin, I., Abidin, H., & Rizman, Z. (2018). Performance evaluation of faster R-CNN on GPU for object detection. Journal of Fundamental and Applied Sciences, 9(3S), 909.
- Bappy, J. H., & Roy-Chowdhury, A. K. (2016). CNN based region proposals for efficient object detection. 2016 IEEE International Conference on Image Processing (ICIP).
- Wang, X., Ma, H., & Chen, X. (2016). Salient object detection via fast R-CNN and low-level cues. 2016 IEEE International Conference on Image Processing (ICIP).
- Zhang, H., Wan, S., Yue, L., Wu, Z., & Zhao, Y. (2015). A new fast object detection architecture combing manually-designed feature and CNN. 2015 8th International Congress on Image and Signal Processing (CISP).
- Guan, T., & Zhu, H. (2017). Atrous Faster R-CNN for Small Scale Object Detection. 2017 2nd International Conference on Multimedia and Image Processing (ICMIP).
- Liu, B., Zhao, W., & Sun, Q. (2017). Study of object detection based on Faster R-CNN. 2017 Chinese Automation Congress (CAC).
- Wei, X., Xie, C., Wu, J., & Shen, C. (2018). Mask-CNN: Localizing parts and selecting descriptors for fine-grained bird species categorization. Pattern Recognition, 76, 704–714.
- He, K., Gkioxari, G., Dollar, P., & Girshick, R. (2017). Mask R-CNN. 2017 IEEE International Conference on Computer Vision (ICCV).
- Du, J. (2018). Understanding of Object Detection Based on CNN Family and YOLO. Journal of Physics: Conference Series, 1004, 012029.
