





Данная работа посвящена прогнозированию и изучению факторов влияющих на удовлетворенность пользователя при поиске в онлайн-картах. Подход к решению задачи осуществлён с помощью регрессионного анализа путем логистической регрессии на основе использования смоделированного поведения пользователей.
Миллионы пользователей сети интернет ежедневно взаимодействуют с поисковыми системами. Они подают запросы, следуют по ссылкам со страницы результата поиска, перефразируют и переформулируют свои запросы, а так же выполняют другие различные задания. Эти действия могут служить ценным источником для улучшения поисковых систем.
В настоящее время сервисы онлайн карт становятся популярнее среди пользователей благодаря возможности настроить масштаб и сменить локацию карты при поиске желаемого географического объекта. Таким образом на экран поиска выводится дополнительная информация. Однако, поисковые системы выдают результаты на основе текущего масштаба карты, в то время как желаемый объект может находиться за ее пределами. Даже если масштаб карты идентичен у некоторых пользователей, они могут искать различную информацию. В связи с этим поднимается вопросы удовлетворенности поиском и удобства пользования сервисом.
К сожалению, опыт показывает, что пользователи довольно редко высказывают желание дать свой ответ на эти вопросы. Однако, необходимую информацию можно извлечь из логов пользователя в поисковых системах. Благодаря тому, что основные поисковые движки обрабатывают миллионы запросов в день, необходимые данные доступны в изобилии.
В условиях того, что подбор необходимой прогнозирующей функции вручную достаточно трудоемок, затратен и непрактичен, исследование в области машинного обучения находит свое применение в этой области задач.
Постановка задачи
В данной работе производится исследование и вычисление прогнозирования удовлетворенности пользователя работой поисковой системы и удобства получения результата. Рассматривается подход к решению задачи с помощью регрессионного анализа путем логистической регрессии на основе использования настоящего поведения пользователей, собранного в результате моделирования обычных взаимодействий с поисковой системой.
В данной работе были поставлены следующие задачи:
- Составить перечень характеристик поиска
- Разработать модель прогнозирования с выбранными характеристиками
- Разработать программу для считывания необходимой информации из логов для последующей реализации моделей предсказания
Исходные данные
Для данной работы были смоделированы журналы действий пользователей в виде файлов представления таблиц баз данных. В каждой строке этой базы содержится время действия, идентификатор пользователя, действия пользователя, а так же дополнительные сведения в зависимости от действия, например, координаты нажатия мыши, содержание запроса.
Карта была поделена на четыре области: область строки запроса, область инструментов поиска, область результатов поиска и область онлайн-карты.
На основе действий были введены следующие факторы: среднее количество символов в запросе, максимальное количество символов в запросе в одном задании, минимальное количество символов в запросе в одном задании, время между запросами, количество запросов, количество запросов без нажатий мыши, количество запросов с нажатием, общее количество нажатий, количество смен локаций, количество движений мыши, время выполнения задания,количество нажатий на область строки запроса, количество нажатий на область инструментов поиска, количество нажатий на область результатов поиска, количество нажатий на карту. Итого рассмотрено пятнадцать факторов.
Также имеем зависимую переменную — удовлетворенность поиском.
Положим, что все пары (идентификатор задания, идентификатор пользователя) являются наблюдениями. Таких наблюдений в журнале 486. Из них в 437 наблюдениях пользователи были удовлетворены, 37 — частично удовлетворены, 12 — не удовлетворены. Для удобства анализа к не удовлетворенным будем относить и частично удовлетворенных. В 424 наблюдениях пользователям сервис был удобен, 62 -- не удобен.
Выбор подхода
В большинстве случаев логистическая регрессия хорошо подходит для описания и проверки гипотез об отношении между зависимой переменной и одной или более независимых переменных, а так же является одной из простейших, но эффективных моделей предсказания.
Простейшую логистическую модель можно описать следующим образом
![]()
где β — коэффициент регрессии, α — нулевой коэффициент. [1]
P(Y = 1) будет являться вероятностью удовлетворенности поиском пользователя.
Алгоритм прогноза
Для считывания данных была реализована программа парсинга на языке с++. На вход подаются три файла, содержащие логи. На выходе программа создает четыре файла: fctr.txt — файл, содержащий матрицу признаков всех наблюдений и вектор зависимых переменных, log.txt содержит последовательность действий пользователя, представленную в виде алфавита, а так же время запроса, непосредственно сам запрос и время завершения задания, answr.txt содержит текст задания предлагаемого на выполнение участнику эксперимента, plot.txt содержит координаты всех нажатий клавиши мыши на карту и номер соответствующего им задания.
Для построения модели логистической регрессии используется программа, разработанная на языке R. На вход подается матрица факторов размерностью 486х15 и вектор ответов 486х1, содержащихся в файле fctr.txt и координаты нажатий на карту из файла plot.txt. Производится их считывание и инициализация переменных.
На основе информации из файла plot.txt выясняются размеры карты, выделяются определенные выше области карты и на них наносятся точки нажатий.
Производится разбиение общей выборки на обучающее и тестовое подмножества с процентным соотношением 75/25 успешных наблюдений к неуспешным в каждом из подмножеств и с соотношением 75/25 количества наблюдений обучающей выборки к количеству наблюдений тестовой выборки. В результате в обучающем подмножестве имеется 364 наблюдения, в тестовом — 122 наблюдения.
Далее происходит построение нескольких моделей предсказывания. Первая модель использует все 15 считываемых факторов, вторая модель использует четыре фактора, связанных с областью нажатия, и всевозможные их произведения. Для построения следующих трех моделей используется пошаговая регрессия на 15 факторах, которая выбирает факторы с помощью информационного критерия Акаике, с прямым, обратным и двухсторонним подходами соответственно. Шестая и седьмая модель так же построены с помощью прямого и двухстороннего подходов пошаговой регрессии на четырех факторах, связанных с областью нажатия.
Результаты
Таблица 1
Весы факторов для различных моделей алгоритмов предсказания удовлетворенности при поиске
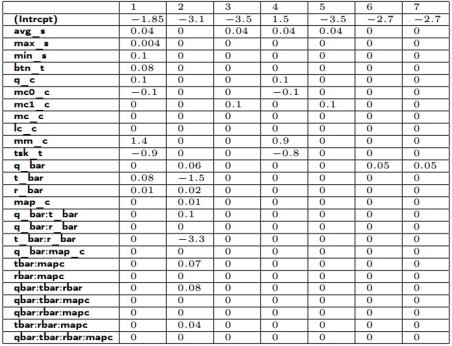
С помощью прямого подхода пошаговой регрессии (модель 3) было выбрано два фактора из пятнадцати: количество запросов с хотя бы одним нажатием на карту и среднее количество символов в запросе; используя обратный подход (модель 4), было выбрано пять факторов: среднее количество символов в запросе, количество запросов, количество запросов без нажатий на карту, количество движений мыши и время выполнения задания. Для модели 5 был выбран двухсторонний подход и, по результатам его работы были выбраны те же факторы, что и в модели 3. Модель 6 и модель 7, модель 3 и модель 5 получились идентичными.
Для первой модели значимыми факторами являются среднее количество символов в запросе, количество запросов и количество движений мыши, для второй, шестой и седьмой -- нажатие в область строки запроса, для третьей — количество запросов с хотя бы одним нажатием на карту, для четвертой — количество запросов, для пятой — количество запросов с хотя бы одним нажатием на карту.
Далее происходит построение таблиц сопряженности для каждой модели. Таким образом определим точность, чувствительность и специфичность каждого алгоритма.
Таблица 2
Оценки качества моделей предсказания удовлетворенности

Чтобы оценить качество классификации, производится ROC-анализ на тестовой выборке. Строится ROC--кривая и вычисляется показатель AUC (площадь под ROC--кривой). На рис.1 представлены их сравнительные графики. Синим цветом выделена ROC--кривая первой модели, ROC--кривые для третьей и пятой моделей совпадают, они выделены на графике черным цветом; зеленая кривая представляет четвертую модель. Коричневым цветом выделена кривая 6 и 7 моделей, фиолетовым -- для 2 модели.
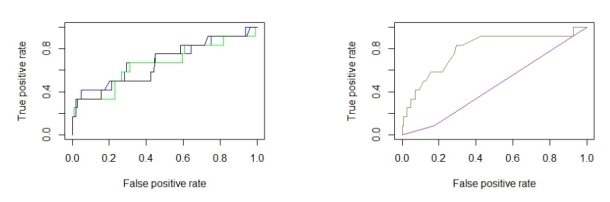
Рис. 1. ROC — кривые моделей
Все модели, исключая модель 2, имеют высокие значения точности и чувствительности, а значит часто выдают истинный результат при положительном исходе. Низкая специфичность всех моделей обусловлена малым количеством наблюдений с отрицательным исходом. Выбираем наилучшую модель, исходя из наибольшего значения AUC. Из табл.1 видно, что наилучший результат продемонстрировали модели 6 и 7, использующие пошаговую регрессию только для факторов, связанных с областью нажатия, включив в алгоритм только нажатия на область запроса. Так же неплохой результат показала модель 1 со значением AUC = 0.6964, что является приемлемым результатом. Остальные модели показали небольшое значение AUC, что значит о неудовлетворительном качестве алгоритма. Наихудший результат показала модель 2, AUC = 0.4545, хуже, чем алгоритм случайного присваивания маркировок, имеющий AUC = 0.5. Данный вывод не позволяет применять эту модель для решения задач на практике.
Заключение
В данной работе производилось исследование и вычисление прогнозирования удовлетворенности пользователя работой поисковой системы. Рассматривался подход к решению задачи с помощью регрессионного анализа путем логистической регрессии.
Для решения представленных выше проблем были достигнуты следующие результаты:
- Реализована программа-парсер, позволяющая вычленить необходимую для исследования и прогнозирования информацию из логов действий пользователей;
- Сформулирована и построена модель для предсказания удовлетворенности пользователя;
- Проанализированы результаты, полученные в ходе решения данной задачи;
Литература:
- Chao-Ying J. Peng, K. L. Lee, Gary M. Ingersoll. An introduction to logistic regression analysis and reporting // EBSCO Publishing. 2002.
