Введение
Криптовалюты (цифровые валюты, которые производится в сети интернет и хранятся на виртуальных кошельках [2]), в частности Bitcoin, стали неотъемлемой частью глобальной финансовой системы [1], она сочетает в себе черты цифрового актива, средства сбережения и инструмента для спекуляций (перепродажа с колеблющейся ценой, с целью получения выгоды). Высокая волатильность Bitcoin делает его крайне чувствительным к внешним факторам, таким как: регуляторные изменения, макроэкономические события и медиа-повестки и прочим. При этом анализ взаимосвязи между ценовыми движениями и информационным фоном остается сложной задачей из-за отсутствия структурированных данных в реальном времени.
Современные исследования показывают, что новостные события могут вызывать краткосрочные ценовые шоки и формировать долгосрочные тренды [3], что подчеркивает необходимость комплексного подхода к сбору и анализу данных.
Предлагаемая в данной статье логика системы решает эту проблему за счет автоматизированного сбора котировок Bitcoin с биржи Bybit и парсинга новостей из авторитетных источников, таких как CoinDesк. Интеграция этих данных в единую базу позволяет исследователям и трейдерам выявлять паттерны, строить прогнозные модели и принимать обоснованные решения.
Таким образом, данная работа имеет высокую актуальность в связи с несколькими факторами:
- Капитализация Bitcoin превысила $1 трлн, а его корреляция с традиционными активами, такими как золото усиливается.
- Исследования демонстрируют, что примерно 60 % резких скачков цены Bitcoin связаны с медиа-событиями, такими как хакерские атаки, регуляторные запреты и другими. Однако большая часть таких данных остается неструктурированной и труднодоступной.
- Ежедневно публикуются тысячи новостей, котировки обновляются каждую секунду, а ручной сбор подвержен ошибкам, что требует эффективных инструментов автоматизации обработки данных, контроля дублей и верификации контента.
Спроектированная в данном исследовании система предоставляет структурированный датасет для ML-моделей прогнозирования цены, базу для академических исследований (например, корреляции медиаактивности и рыночной динамики).
Выбор инструментов для сбора данных
Котировки Bitcoin: время, цены, объемы и новости: текст, метаданные имеют четкую структуру, что подходит под определение реляционной модели базы данных, поэтому в данной работе было принято выбрать реляционную СУБД (Система Управления Базы Данных) PostgreSQL — реляционная СУБД с открытым исходным кодом, которая идеально подходит для задач, требующих надежности, структурированного хранения и сложных запросов. В PostgreSQL есть встроенные функции для работы с временными рядами, например, date_trunc, generate_series, а также данная СУБД имеет встроенные типы данных timestamp и interval, что делает PostgreSQL эффективным решением для хранения и анализа финансовых данных с временными метками [10]. Так же данная СУБД гарантирует целостность данных при параллельных операциях и поддерживает JSONB для хранения тегов новостей. Использование типа данных JSONB в реляционных СУБД, таких как PostgreSQL, представляет собой оптимальный компромисс, позволяя хранить полу структурированные данные с сохранением возможности выполнения сложных запросов и поддержки ACID-транзакций [6].
Для работы с БД (базой данных) было принято использовать Python — язык с низким порогом входа, богатой экосистемой библиотек и поддержкой интеграции с внешними системами. Python предлагает гибкость, скорость разработки и простоту обучения в связи с низким порогом входа, наличием массы документации, курсов и прочих полезных ресурсов, так же для дальнейших исследований, анализа данных и прогнозирования возможна интеграция с Machine Learning, благодаря готовым инструментам, например, ‘scikit-learn’, ‘TensorFlow’.
Python позволяет работать с базой как с объектами Python, минимизируя написание «сырого» SQL, использовать `psycopg2.extras.execute_batch` для быстрой вставки больших объемов данных и поддержки JSON для хранения нестандартных полей новостей в формате JSONB с возможностью запросов. Экосистема Python, включая библиотеки pandas для манипуляции данными и requests для работы с API, обеспечивает беспрецедентную скорость разработки и гибкость при построении ETL-конвейеров для финансовой аналитики [8].
Данный стек позволяет сосредоточиться на решении задач, а не на преодолении технических ограничений.
Проектирование и создание базы данных
Для сбора данных и хранения новостных статей и котировок связанных с Bitcoin нам необходимо создать 2 отношения (таблицы), пусть это будут:
articles, предназначенное для хранения новостных статей, связанных с Bitcoin (таблица 1);
btc_quotes, для сбора информации о котировках криптовалюты (таблица 2).
Таблица 1
Описание отношения articles
|
Поле |
Тип данных |
Ограничения |
Назначение | |
|
id |
serial4 |
PRIMARY KEY |
Уникальный идентификатор записи (автоинкремент) | |
|
article_language |
text |
NOT NULL |
Язык статьи (например, en, ru) | |
|
title |
text |
NOT NULL |
Заголовок статьи | |
|
full_text |
text |
NOT NULL |
Полный текст статьи | |
|
author |
varchar(255) |
— |
Имя автора (если указано) | |
|
publish_dttm |
timestamp |
— |
Дата и время публикации статьи | |
|
modified_dttm |
timestamp |
— |
Дата и время последнего изменения статьи | |
|
url |
varchar(512) |
NOT NULL, UNIQUE |
Уникальный URL статьи | |
|
tags |
_text (массив) |
— |
Список тегов (например, {strategy,market-analysis}) | |
|
content_hash |
bpchar(32) |
NOT NULL, UNIQUE |
MD5-хеш текста статьи для контроля уникальности | |
|
last_updated |
timestamp |
DEFAULT CURRENT_TIMESTAMP |
Дата и время последнего обновления записи в БД | |
1. Первичный ключ : articles_pkey (id) — уникальная идентификация записей.
2. Уникальные ограничения :
articles_url_key (url) — предотвращение дублирования статей по URL;
articles_content_hash_key (content_hash) — гарантия уникальности контента.
3. Индексы : idx_content_hash — оптимизация поиска по хешу.
Таблица 2
Описание отношения btc_quotes
|
Поле |
Тип данных |
Ограничения |
Назначение |
|
report_dttm |
timestamp |
PRIMARY KEY, NOT NULL |
Временная метка начала интервала (например, 2025–05–01 00:00:00) |
|
open_price |
numeric(20, 2) |
— |
Цена открытия за интервал. Пример: 45000.50 |
|
high_price |
numeric(20, 2) |
— |
Максимальная цена за интервал. Пример: 45200.75 |
|
low_price |
numeric(20, 2) |
— |
Минимальная цена за интервал. Пример: 44800.30 |
|
close_price |
numeric(20, 2) |
— |
Цена закрытия интервала. Пример: 45100.60 |
|
volume |
numeric(20, 2) |
— |
Объем торгов в базовой валюте (например, USDT). Пример: 1200.50 |
При проектировании схемы для хранения временных рядов (котировок) было принято использование временной метки report_dttm в качестве первичного ключа, что является стандартной и эффективной практикой, обеспечивающей уникальность записей и быстрый доступ по времени [7] и индексы: idx_report_dttm, что оптимизирует запросы, фильтрующие данные по времени, например, выборка за определенный день.
Автоматизированный сбор и обработка новостных событий Bitcoin
В современной цифровой экономике новостной фон играет критическую роль в формировании рыночных тенденций криптовалют. Для систематического анализа влияния информационных факторов на динамику Bitcoin можно разработать автоматизированную систему сбора новостей, которая будет ежедневно обрабатывать актуальные публикации из авторитетного источника CoinDesk (новостной сайт, который специализируется на биткоинах и цифровых валютах), обеспечивая структурированное хранение данных для последующего анализа корреляции с котировками.
Парсинг — это процесс автоматизированного извлечения данных с веб-страниц. Анализируя структуру HTML-документа (HTML — язык гипертекстовой разметки), система может находить и извлекать нужную информацию, преобразуя неструктурированные веб-данные в формат, пригодный для анализа.
Для поиска необходимой информации мы можем использовать библиотеку BeautifulSoup, которая предоставляет интуитивно понятные методы для навигации по DOM-дереву HTML-документа (find, find_all), что делает ее неким стандартом для извлечения структурированной информации из веб-страниц при парсинге новостей [9], основные методы поиска:
- По тегу: soup.find('div')
- По классу: soup.find(class_='article-title')
- По атрибуту: soup.find(property='og:published_time')
- Комбинированный поиск: soup.find('div', class_='meta-info')
Пример поиска автора статьи из HTML кода (Результат: «Jane Doe»):
author = soup.find('span', class_='author').text.replace('By ', '')
В качестве ключевых компонентов данного блока, можно выделить:
- RSS-парсер для получения списка свежих статей.
- HTML-парсер для извлечения контента и метаданных.
- Модуль контроля качества данных.
- Интеграционный слой с базой данных PostgreSQL.
- Механизм обработки ошибок с ротацией прокси и повторными попытками.
Взаимодействие с API для сбора котировок с биржи
Работа с API — основа современных систем алгоритмической торговли и финансового анализа, позволяющая автоматизировать сбор данных в реальном времени. API — это набор правил и протоколов, позволяющих разным приложениям взаимодействовать друг с другом [4]. В контексте финансовых рынков API бирж предоставляет программный доступ к историческим данным о котировках, торговым операциям, статусам ордеров и т. д. Общая схема работы с API представлена на рисунке 1.

Рис. 1. Общая схема работы с API
Ключевые аспекты API-взаимодействия:
1. Аутентификация для публичных данных не требуется, для приватных запросов используются:
API-ключи;
цифровые подписи;
HMAC-шифрование.
2. Типы запросов (Рисунок 2).
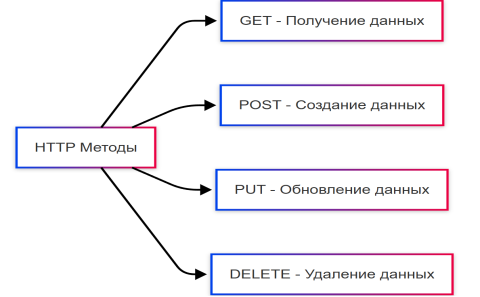
Рис. 2. Типы запросов
3. Форматы данных: JSON, XML, Protocol Buffers, WebSockets для реального времени.
4. Статус-коды
200 OK — успешный запрос;
400 Bad Request — неверные параметры;
401 Unauthorized — проблемы аутентификации;
429 Too Many Requests — превышен лимит запросов;
500 Internal Server Error — ошибка сервера.
5. Режимы работы
синхронный (один запрос — один ответ);
асинхронный (long-polling, WebSockets);
потоковая передача данных.
Особенности финансовых API [5]:
1. Рейт-лимиты — ограничения на количество запросов в минуту/секунду (например, 60 запросов/мин для BYBIT).
2. Пагинация — возврат данных порциями (например, 200 свечей за запрос).
3. Временные метки: единообразие формата (UNIX timestamp в миллисекундах), учет часовых поясов (обычно UTC).
4. Стабильность и версионирование:
версии API (/v1/, /v2/, /v5/);
резервные эндпоинты;
уведомления о deprecated-функционале.
Оптимизация работы с API:
- Кеширование повторяющихся запросов
- Пакетная обработка (batching)
- Экспоненциальная задержка при ошибках
- Компрессия данных (gzip)
- Параллельные запросы
Для выполнения необходимых задач, можно разработать модуль, который будет выполнять следующие задачи:
- Устанавливает соединение с API биржи BYBit.
- Извлекает исторические данные по BTC/USDT.
- Трансформирует данные в структурированный формат.
- Загружает данные в базу PostgreSQL.
- Обеспечивает целостность данных.
Ключевые особенности реализации:
- Для обхода ограничений API (200 свечей за запрос) необходимо реализовать пакетную обработку с автоматическим расчетом количества запросов.
- Определение последней доступной даты в БД, чтобы загружать только новые данные, минимизируя нагрузку.
- Перед вставкой данных необходимо выполнять удаление записей за тот же период для предотвращения дублирования.
- Поэтапные проверки (флаги выполнения) и детальное логирование, которые позволяют быстро диагностировать проблемы.
- Использовать явное преобразование типов, что гарантирует корректное хранение данных в PostgreSQL.
Итоговое наполнение таблиц
Реализованная система позволяет воспользоваться оркестраторами (специализированные инструменты для автоматизированного управления, координации и интеграции разнородных данных из множества источников в единый слаженный поток), например, Apache Airflow, для того, что бы поставить Python «скрипты» на регулярное обновление, которое будет производиться без участия человека, что позволит иметь доступ к нужным в исследованиях, проектировании и т. д. данным с необходимой глубиной (длительностью) и минимизировать затраты на сбор и обновление данных. Результаты работа системы (данные) представлены на рисунках 3–5.
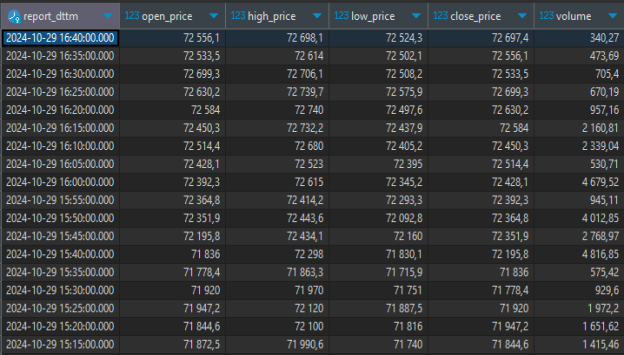
Рис. 3. Данные о котировках биткоин
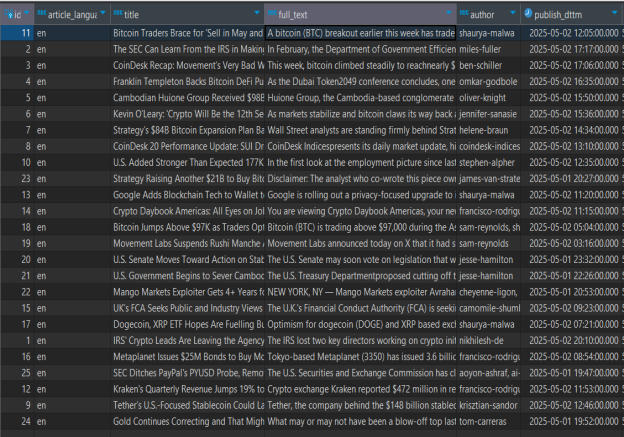
Рис. 4. Новостные события (часть 1)
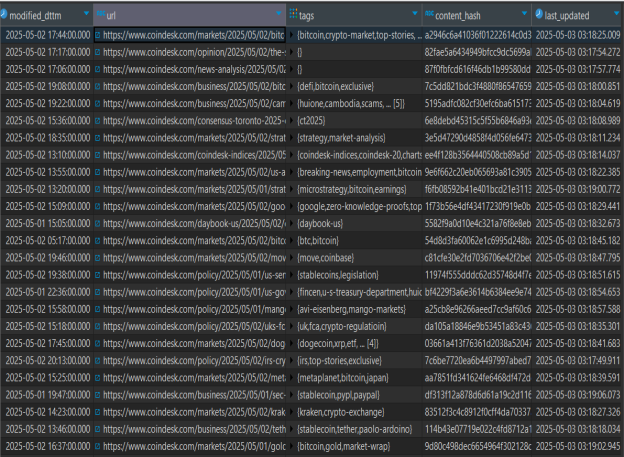
Рис. 5. Новостные события (часть 2)
Литература:
- Артемьев К. И. Блокчейн: возникновение, особенности использования и регулирования / К. И. Артемьев // Отечественная юриспруденция. — 2018. — № 4. — С. 60–64.
- Дулатова Н. В. Цифровая валюта: перспективы и анализ рынка криптовалютных бирж России и зарубежных стран / Н. В. Дулатова // Вестн. Том. гос. ун-та. Право. — 2022. — № 46. — С. 150–163.
- Овсяникова П. А. Биткоин: факторы, влияющие на волатильность криптовалюты / П. А. Овсяникова // Электронный вестник Ростовского социально-экономического института. — 2016. — № 2. — С. 254–260.
- Палаш Б. В. API скрипты и особенности их использования / Б. В. Палаш // Форум молодых ученых — 2019 — № 1–2 — С. 29.
- Bybit. Bybit API Documentation: Market Data Endpoints — Kline / Bybit // Bybit Developers. — 2024.
- Celko J. Joe Celko's Complete Guide to NoSQL: What Every SQL Professional Needs to Know about Non-Relational Databases / J. Celko // Morgan Kaufmann. — 2018. — P. 145.
- Date C. J. Database Design and Relational Theory: Normal Forms and All That Jazz \ C. J. Date \\ Apress. — 2019. — 2nd ed. — P. 92.
- McKinney W. Python for Data Analysis: Data Wrangling with pandas, NumPy, and Jupyter \ W. McKinney \\ O'Reilly Media. — 2022. — 3rd ed. — P. 18.
- Mitchell R. Web Scraping with Python: Collecting More Data from the Modern Web \ R. Mitchell \\ O'Reilly Media. — 2018. — 2nd ed. — P. 57.
- PostgreSQL Global Development Group. PostgreSQL 15 Documentation: Chapter 9. Functions and Operators / PostgreSQL Global Development Group // PostgreSQL Documentation. — 2023.

