В данной статье рассмотрена тема об использовании метода распознавания речи как одного их способа идентификации. Речь состоит из двух компонентов — это голосовые и шумовые источники звука. Используя один из компонентов образования речи и была подробно рассмотрена модель речевой идентификации, которая основана на гласных звуках.
Ключевые слова: информационная безопасность, речевая идентификация, модель речевой идентификации.
В нашем мире тяжело представить жизнь без современных технологий. Одна из таких технологий связана с возможностью управлять электронными системами голосом. Крупные компании уделяют внимание данному направлению, так как голос — это уникальный слепок человека, как и отпечатки пальцев. По голосу можно идентифицировать человека, понять его настроение.
Речь как инструмент управления состоит из следующих компонентов: синтез, распознание, понимание. Для того, чтоб понимать речь необходимо грамматические и фонетические знания языка. Анализ синтеза речи основан на модели излучении звуковых волн речевого сигнала.
В речеобразовании существуют голосовые и шумовые источники звуков. Голосовые — основаны на тонах речи при колебании голосовых связок. Такие звуки делятся на гласные и согласные. Гласные звуки построены на частотах основного тона. Шумовые — основаны на дыхании человека (выдох воздуха из лёгких во время разговора).
Построим модель, преимущественно основанную на гласных звуках, где входной сигнал x(t) основан на голосовых связках, проходящий через речевой резонатор N-e и выходящий через речевой сегмент y(t). Из этих условий получаем математическую модель, сумма амплитуд гармоник которой проходит через резонансную систему
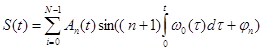
где: n=0, 1, 2… — номер гармоники основного тона;
An — амплитуды гармоник;
w0 — частота основного тона, рад/сек;
jn — начальная фаза гармоник;
S (t) — конечный продукт генеративной и резонансной системы.
Таким образом, имея только выходной сигнал S(t), необходимо рассчитать резонансные и генеративные составляющие.
Для этого необходимо разложить сигнал в квазигармоничный спектр и выбрать в нём составляющую соответствующей частоте тона.
![]() ,
, ![]() ,
,![]() . (1)
. (1)
Проводя сравнение с методами классической оценкой частоты основного тона речи, задача (1) прямо пропорциональна задаче генерации кандидатов искомого периода основного тона, но в отличии от кросскорреляционных подходов тут происходит создание заранее известных функций.
Таким образом TL,N вместе с начальным сигналом SN на входе системы осуществляя выбор функции из основного тона речи. Набор параметров на выходе данной системы, показывающих частоту тона речи в виде Amp — сигнальная амплитуда, F0 — характеристика частоты и T0N — трека функции. Выбор квазигармонической составляющей соответствующей частоте основного тона речи формализуем некоторой функцией выбора:
![]() (2)
(2)
Исходя из этого процесс протекающий в блоке постобработки типовых оценок, в селекторе (2) срабатывает правило решающего отбора идеального кандидата с уточнением последующего значения частоты тона речи.
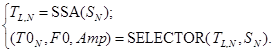 (3)
(3)
Следовательно, соединив (1), (2) модель возможно описать концепции сингулярного оценивания. Тогда, если (3) это производная равенства (1) и определяется решением задачи разложения сингулярного спектрального временного ряда из одномерного в многомерный, то для производной равенства (2) требуется дополнительное рассмотрение.
Используя данную модель, основанную на гласных звуках, можно построить более совершенную модель для речевой идентификации, которая может использоваться в разных областях современной жизни, таких как информационная безопасность, сферы обслуживания, торговли и т. п. Немаловажная особенность и уникальность технологии речевого распознавания и управления это неоценимая помощь людям с ограниченными возможностями.
Литература:
- Вольф Д. А. Построение математической модели селектора сингулярного эстиматора мгновенной частоты основного тона речи // Технические науки — от теории к практике: сб. ст. по матер. XLI междунар. науч.-практ. конф. № 12(37). — Новосибирск: СибАК, 2014.
- Абляев, С. В. Управление человеческими ресурсами на основе компьютерных технологий / С. В. Абляев. — М.: Финансы и статистика, 2006.
- Мельников Защита информации в компьютерных системах / Мельников, Викторович Виталий. — М.: Финансы и статистика; Электроинформ, 2008.
- Соколов, А. В. Защита информации в распределенных корпоративных сетях и системах / А. В. Соколов, В. Ф. Шаньгин. — М.: ДМК Пресс, 2002.

