В деятельности современных учреждений обращения и заявки выступают одним из основных источников информации о взаимодействии с гражданами, сотрудниками, подразделениями и пользователями услуг. В большинстве случаев такие записи используются для регистрации факта поступления запроса, назначения исполнителя и контроля текущего состояния обработки. Однако при накоплении значительного массива данных обращения и заявки приобретают дополнительное аналитическое значение, поскольку позволяют оценивать структуру входящего потока, сроки исполнения, уровень просрочки и распределение нагрузки между исполнителями.
С. О. Репецкий [1] рассматривает обработку заявок как значимый процесс в системе поддержки, связанный с управлением инцидентами, диспетчеризацией и сопровождением запросов. Такой подход показывает, что заявка является не только единичным сообщением о проблеме, но и элементом управляемого процесса, имеющего жизненный цикл, ответственного исполнителя, статус и результат обработки. А. П. Бойко [2] при описании корпоративной информационной системы обработки заявок подчеркивает значение автоматизированного учета заявок и их сопровождения. Следовательно, разработка аналитической подсистемы должна опираться на уже существующую логику обработки заявок, но расширять ее за счет статистической интерпретации накопленных данных.
Информационная поддержка учреждения предполагает использование данных для оценки состояния управляемого объекта и обоснования последующих действий. С. В. Тарарыкин [3] отмечает, что информационная поддержка управленческих решений основывается на мониторинге и оценке показателей, отражающих состояние объекта управления. Применительно к обращениям и заявкам таким объектом является процесс их обработки, а показателями выступают количество поступивших записей, средний срок исполнения, доля просроченных обращений, нагрузка исполнителей и динамика потока по периодам. Поэтому подсистема статистического анализа должна рассматриваться не как вспомогательный отчетный модуль, а как средство преобразования операционных данных в аналитическую информацию.
Назначение разрабатываемой подсистемы состоит в автоматизированной обработке массива обращений и заявок, проверке корректности входных данных, сохранении информации в локальной базе, расчете статистических показателей и формировании аналитических отчетов. Исходными данными для подсистемы выступает CSV-файл, содержащий сведения об обращениях и заявках. К таким сведениям относятся идентификатор записи, дата создания, дата закрытия, категория, канал поступления, подразделение, исполнитель, статус, приоритет, тема и текстовое описание. Результатом работы подсистемы являются текстовые, табличные и структурированные отчеты, а также сохраненные в базе расчетные метрики.
Общая логика работы подсистемы может быть представлена следующим образом:
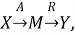
где
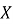
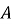
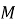
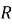
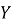
Архитектура подсистемы построена по модульному принципу. Такой подход позволяет разделить программное решение на логически самостоятельные компоненты, каждый из которых отвечает за определенный этап обработки данных. Е. А. Миних и Н. С. Федоренко [4] при рассмотрении архитектуры приложения для учета заявок обслуживания компьютерной техники в центре информационных технологий вуза показывают, что автоматизация заявочного процесса требует выделения структурных компонентов, отвечающих за прием, учет и сопровождение заявок. В разрабатываемой подсистеме эта логика дополнена аналитическим контуром, предназначенным для расчета статистических показателей и формирования отчетности.
В состав подсистемы входят модуль импорта и проверки данных, модуль хранения, аналитический модуль, модуль анализа просрочки, модуль обнаружения аномалий и модуль отчетности. Модуль импорта обеспечивает чтение CSV-файла и преобразование строк в объекты предметной модели. Модуль валидации проверяет наличие обязательных полей, корректность дат, допустимость статусов и приоритетов, уникальность идентификаторов и согласованность временных параметров. Модуль хранения отвечает за запись корректных данных в локальную базу. Аналитический модуль рассчитывает сводные показатели, группировки, динамику и показатели просрочки. Модуль отчетности формирует результаты в текстовом, CSV- и JSON-форматах.
Для систематизации состава подсистемы используется таблица 1.
Таблица 1
Состав подсистемы статистического анализа обращений и заявок
|
Модуль подсистемы |
Назначение |
Результат работы |
|
Импорт данных |
Чтение CSV-файла и разбор строк |
Исходный массив записей |
|
Валидация |
Проверка обязательных полей, дат, статусов и идентификаторов |
Набор корректных записей и журнал ошибок |
|
Хранение данных |
Сохранение записей, справочников и истории статусов |
Локальная база данных |
|
Статистический анализ |
Расчет количества, долей, средних значений и группировок |
Сводные аналитические показатели |
|
Анализ просрочки |
Сравнение фактических сроков с нормативными |
Перечень просроченных записей и уровень просрочки |
|
Обнаружение аномалий |
Выявление нетипичных сроков обработки и резкого роста потока |
Список потенциально проблемных ситуаций |
|
Отчетность |
Формирование TXT-, CSV- и JSON-отчетов |
Итоговые материалы для анализа |
Источники: составлено автором на основе [1], [2], [4].
Для постоянного хранения данных используется SQLite. Согласно SQLite Documentation [5], SQLite предоставляет интерфейс для использования в программах на C и C++, что позволяет применять его в локальных прикладных решениях без развертывания отдельного серверного программного обеспечения. В подсистеме база данных используется для хранения исходных записей, справочников, истории статусов, журнала ошибок импорта и рассчитанных метрик. Такая организация позволяет рассматривать базу как локальное аналитическое хранилище.
Особое значение имеет обеспечение целостности данных при импорте и сохранении результатов. Согласно SQLite Documentation [6], транзакция может начинаться командой BEGIN и завершаться командами COMMIT или ROLLBACK. В программной реализации это позволяет фиксировать изменения только при успешном выполнении операции и отменять их при возникновении ошибки. Для подсистемы статистического анализа такая возможность важна, поскольку некорректное сохранение данных может привести к искажению последующих расчетов.
Программная реализация подсистемы выполнена на языке C++20. Для организации сборки используется CMake. По данным CMake Documentation [7], данное средство позволяет решать типовые задачи сборки программных проектов и организовывать работу с исходными файлами и зависимостями. Это соответствует модульной структуре подсистемы, в которой программный код разделен на компоненты импорта, хранения, аналитики и отчетности.
Аналитическая часть подсистемы основана на расчете статистических показателей. К числу основных показателей относятся общее количество записей, количество открытых и закрытых обращений, средний и медианный срок исполнения, доля просроченных записей, распределение обращений по категориям, исполнителям, подразделениям и периодам. Одним из ключевых показателей является признак просрочки, который может быть представлен следующим образом:
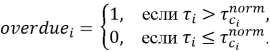
где
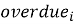
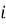
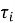
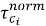
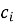
Практическая значимость подсистемы заключается в том, что она позволяет использовать массив обращений и заявок не только как архив записей, но и как источник информационной поддержки учреждения. Результаты статистического анализа могут применяться для выявления наиболее частых категорий обращений, оценки нагрузки на подразделения и исполнителей, контроля сроков, обнаружения проблемных направлений и анализа динамики поступления заявок. Это повышает обоснованность управленческих решений, поскольку выводы формируются на основе данных, а не только на основании субъективной оценки ситуации.
Использование подсистемы может быть особенно полезным в тех случаях, когда учреждение обрабатывает значительный поток однотипных запросов. В такой ситуации ручной анализ становится трудоемким и не всегда позволяет своевременно выявлять отклонения. Автоматизированная подсистема сокращает время подготовки отчетов, повышает воспроизводимость расчетов и обеспечивает единый подход к оценке обращений и заявок. При этом модульная архитектура позволяет в дальнейшем расширять функциональность, добавляя новые виды отчетов, дополнительные методы анализа и иные форматы входных данных.
Подсистема статистического анализа обращений и заявок является инструментом информационной поддержки учреждения, поскольку обеспечивает переход от регистрации отдельных записей к аналитической оценке процесса их обработки. В рамках подсистемы реализуются загрузка и проверка данных, хранение информации в локальной базе, расчет статистических показателей, анализ просрочки, выявление аномалий и формирование отчетных материалов.
Модульная архитектура подсистемы позволяет разделить функции импорта, хранения, аналитики и отчетности, что повышает сопровождаемость и расширяемость программного решения. Использование SQLite обеспечивает локальное хранение данных и результатов расчетов, а применение CMake поддерживает модульную организацию проекта на C++.
Практическая значимость разработанной подсистемы состоит в возможности ее применения для оценки структуры входящего потока обращений, сроков исполнения, уровня просрочки и нагрузки исполнителей. Полученные аналитические результаты могут использоваться для выявления проблемных направлений, подготовки отчетов и обоснования управленческих решений в учреждении.
Литература:
- Репецкий С. О. Обработка заявок в IT Service Desk.
- Бойко А. П. Корпоративная информационная система обработки заявок на обслуживание.
- Тарарыкин С. В. Информационная поддержка принятия управленческих решений в вузе.
- Миних Е. А., Федоренко Н. С. Разработка архитектуры приложения для ведения учета заявок обслуживания компьютерной техники в центре информационных технологий вуза.
- SQLite Documentation. An Introduction To The SQLite C/C++ Interface.
- SQLite Documentation. Transaction.
- CMake Documentation. CMake Tutorial.

