В условиях цифровой трансформации организаций и постоянного роста объемов данных особую значимость приобретает обеспечение качества информации, используемой в аналитической, управленческой и регламентированной отчетности. Современные корпоративные информационные системы функционируют в среде высокой интеграционной нагрузки: данные поступают из множества автоматизированных систем, проходят последовательные этапы обработки, трансформации и агрегирования, после чего используются для формирования аналитических показателей и принятия управленческих решений. При этом даже незначительные ошибки в данных способны привести к серьезным последствиям: искажению итоговых показателей, нарушению сроков подготовки отчетности, увеличению трудозатрат аналитических подразделений и снижению достоверности управленческой информации [1].
Особенно актуальной данная проблема становится в процессах обработки финансовых данных, где данные характеризуются высокой степенью детализации, большим количеством аналитических признаков и сложной структурой взаимосвязей между источниками. В подобных процессах данные проходят многоэтапную обработку в аналитических витринах и OLAP-структурах, причем результаты каждого этапа становятся основой для последующих расчетов. В результате ошибка, допущенная на раннем этапе обработки, может распространяться по всей цепочке, затрагивая значительное количество зависимых расчетов и отчетных форм.
На практике контроль качества данных в подобных процессах часто выполняется вручную либо частично автоматизирован с использованием разрозненных SQL-запросов, Excel-файлов и локальных проверок. Аналитики осуществляют сверку данных между различными источниками, контролируют полноту загрузки, проверяют корректность агрегатов, анализируют отклонения между периодами и отслеживают согласованность данных на различных этапах обработки. Однако при росте объемов информации и увеличении количества обработок ручной подход становится неэффективным. Существенно возрастают временные затраты на выполнение проверок, увеличивается риск пропуска ошибок, а воспроизводимость результатов начинает зависеть от квалификации и опыта конкретного специалиста.
Дополнительной проблемой является ограниченность ресурсов аналитических подразделений. Значительная часть рабочего времени специалистов тратится не на анализ причин отклонений и развитие бизнес-логики, а на выполнение повторяющихся технических операций. При этом часть проверок иногда в принципе невозможно выполнить вручную из-за большого объема данных, сложности вычислений или необходимости оперативной реакции на отклонения. Все это приводит к формированию устойчивого запроса на автоматизацию процессов контроля качества данных.
В научной литературе и корпоративной практике существует несколько основных подходов к решению данной задачи. Наиболее распространенным направлением является использование ETL-платформ и специализированных систем управления качеством данных (Data Quality Management). Такие решения позволяют централизованно реализовывать правила проверки и автоматизировать часть операций контроля [2]. Однако внедрение подобных систем часто сопровождается высокой стоимостью разработки и сопровождения, длительным циклом интеграции, а также сложностью оперативной адаптации под изменяющиеся бизнес-требования.
Другим направлением являются методы интеллектуального анализа данных и технологии машинного обучения, позволяющие выявлять аномалии и прогнозировать отклонения [3]. Несмотря на высокий потенциал подобных решений, их применение в корпоративной среде ограничивается необходимостью накопления обучающих выборок, сложностью интерпретации результатов и повышенными требованиями к информационной безопасности. Кроме того, для многих задач контроля качества данных критически важны прозрачность логики проверки и полная воспроизводимость результатов, что затрудняет использование «непрозрачных» моделей.
В этих условиях особую практическую значимость приобретают подходы, основанные на использовании SQL-инструментария как самостоятельной платформы автоматизации контроля качества данных. Преимуществами такого подхода являются предсказуемость результатов, возможность интеграции в существующую архитектуру обработки данных, отсутствие необходимости модификации исходных систем и высокая скорость адаптации бизнес-правил. Кроме того, SQL-процедуры позволяют реализовывать сложные проверки непосредственно на уровне хранилищ и аналитических витрин, минимизируя необходимость промежуточных выгрузок и ручной обработки данных.
В рамках проведенного исследования был разработан и апробирован подход к автоматизации контроля качества данных операционных расходов на основе автономной цепочки SQL-процедур, встроенной в существующий процесс обработки данных. Архитектура решения была построена таким образом, чтобы запуск процедур контроля выполнялся автоматически после завершения загрузки и обработки аналитических витрин (рис. 1). При этом каждая процедура реализовывала отдельный класс проверок: контроль полноты данных, проверку корректности агрегатов, анализ отклонений между отчетными периодами, поиск дублирующихся записей и проверку согласованности данных между взаимосвязанными источниками.
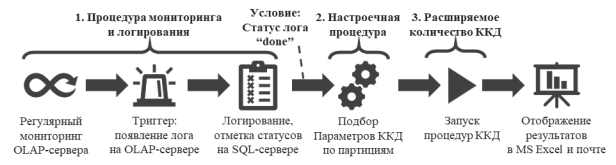
Рис. 1. Последовательность автоматизированного процесса
Одной из особенностей предложенного подхода стала реализация динамической параметризации SQL-процедур. Использование параметров позволило унифицировать механизм проверок и обеспечить возможность повторного применения процедур для различных наборов данных без изменения программной логики. Это существенно упростило сопровождение решения и повысило скорость адаптации проверок при изменении структуры аналитических витрин или бизнес-требований.
Дополнительно в рамках исследования был реализован механизм централизованного логирования результатов проверок. Информация о выявленных отклонениях, времени выполнения процедур и статусах обработки сохранялась в отдельной таблице, что обеспечило возможность последующего анализа данных и формирования отчетности по результатам контроля. Наличие централизованного журнала позволило повысить прозрачность процессов и упростить поиск причин возникновения ошибок.
Практическая апробация разработанного подхода продемонстрировала существенное повышение эффективности процессов контроля качества данных. В результате внедрения автоматизированной цепочки SQL-процедур время выполнения отдельных критичных проверок сократилось с 63 до 3 минут, что соответствует ускорению более чем в 20 раз. В среднем по реализованным сценариям контроля было достигнуто ускорение процессов в 5–10 раз, а часть проверок, ранее невыполнимых вручную из-за объема данных и сложности вычислений, стала доступна для регулярного использования. Автоматизация позволила существенно сократить вовлеченность аналитиков и разработчиков в рутинные операции, аналитики сосредоточились преимущественно на анализе выявленных отклонений и развитии логики проверок. Дополнительным эффектом стало более раннее выявление ошибок.
Полученные результаты подтверждают эффективность применения SQL-ориентированного подхода для автоматизации контроля качества данных в корпоративных информационных системах. Предложенное решение обладает высокой адаптивностью, не требует существенного изменения архитектуры существующих процессов и может быть масштабировано.
Литература:
- Горленко, О. А. « Статистические методы в управлении качеством: учебник и практикум для вузов » / О. А. Горленко, Н. М. Борбаць. — Москва: Юрайт, 2020. — 306 с.
- Исаев, Г. Н. « Управление качеством информационных систем: учебное пособие » / Г. Н. Исаев. — Москва: ИНФРА‑М, 2020. — 247 с.
- Шелухин, О. И. « Сетевые аномалии. Обнаружение, локализация, прогнозирование » / О. И. Шелухин. — Москва: Техносфера, 2019. — 448 с.

