This paper presents an original framework for assessing the production readiness of machine learning systems (Production Readiness Level, PRL) in an enterprise context. Drawing on the Technology Readiness Level (TRL) concept widely used in aerospace and defense, the author proposes a ten-level maturity scale for ML systems covering data quality, model validation, infrastructure readiness, drift monitoring, and operational resilience. The framework is formalized through a system of quantitative metrics and quality gates — checkpoints whose passage is a mandatory condition for advancing to the next maturity level. Methods for detecting and correcting concept drift in production ML systems are examined in detail, employing statistical criteria (PSI, KL divergence, Kolmogorov–Smirnov test) and algorithmic detectors (ADWIN, Page–Hinkley). Practical validation of the framework was conducted on 37 real-world enterprise AI deployment projects (based on the experience of Insight AI), resulting in a reduction of pilot-only project outcomes from 68 % to 22 %. The findings may benefit organizations undertaking digital transformation using machine learning technologies.
Keywords: machine learning, production readiness, MLOps, quality gates, concept drift, model monitoring, enterprise AI, ML system lifecycle, data drift.
Введение
Современные корпорации всё активнее инвестируют в технологии машинного обучения (ML) и искусственного интеллекта (ИИ), стремясь автоматизировать бизнес-процессы, повысить точность прогнозирования и снизить операционные издержки. Согласно аналитическим данным McKinsey, в 2024 году 72 % организаций крупного бизнеса заявляли об использовании ИИ хотя бы в одном бизнес-процессе [1]. Однако переход от экспериментальных прототипов (proof-of-concept, PoC) к устойчиво работающим промышленным системам остаётся критическим барьером: по данным Gartner, до 85 % ML-проектов не достигают стадии промышленной эксплуатации [2, с. 14].
Причины этого разрыва носят системный характер и связаны не столько с качеством самих алгоритмов, сколько с недостаточной зрелостью процессов инженерии данных, инфраструктурной готовности, мониторинга и организационного сопровождения. В научной литературе данная проблема обозначается как «последняя миля ML» (last-mile ML problem) [3] и включает вопросы воспроизводимости экспериментов, управления версиями данных и моделей, автоматизации конвейеров переобучения, обнаружения дрифта и обеспечения аудируемости решений.
Существующие подходы к оценке зрелости ML-систем, такие как модели MLOps Maturity (Microsoft) [4] и ML Test Score (Google) [5], предлагают полезные эвристики, однако не формализованы в виде единой шкалы с количественными критериями перехода между уровнями. Это затрудняет их использование в корпоративном контексте, где решения о запуске систем в промышленную эксплуатацию должны быть обоснованы измеримыми показателями и одобрены кросс-функциональными комитетами.
Целью настоящего исследования является разработка формализованного фреймворка оценки production-readiness ML-систем, включающего: (1) десятиуровневую шкалу зрелости Production Readiness Level (PRL); (2) систему количественных метрик и quality gates для каждого уровня; (3) методологию обнаружения и коррекции concept drift; (4) практические рекомендации по внедрению фреймворка в корпоративные процессы.
Научная новизна работы состоит в следующем:
— — впервые предложена формализованная десятиуровневая шкала PRL, адаптированная для ML-систем в корпоративном контексте, с количественными критериями перехода между уровнями;
— разработана система quality gates, интегрирующая метрики качества данных, производительности моделей, инфраструктурной готовности и операционной устойчивости;
— предложена комплексная методология мониторинга дрифта, объединяющая статистические критерии (PSI, KL-дивергенция, тест Колмогорова — Смирнова) с алгоритмическими детекторами (ADWIN, Page — Hinkley) в единую систему принятия решений о переобучении;
— проведена практическая апробация фреймворка на реальных проектах внедрения ИИ-систем, подтвердившая его эффективность в снижении доли проектов, не достигших промышленной эксплуатации.
1. Обзор литературы и существующих подходов
Проблематика перехода ML-систем от экспериментальной стадии к промышленной эксплуатации находится на пересечении нескольких исследовательских направлений: MLOps (Machine Learning Operations), software engineering for ML и AI governance.
1.1. Концепция Technology Readiness Level и её адаптации.
Концепция Technology Readiness Level (TRL) была разработана NASA в 1970-х годах для оценки зрелости технологий в аэрокосмической отрасли и впоследствии получила широкое распространение в оборонной промышленности, энергетике и других наукоёмких секторах [6]. Шкала TRL включает 9 уровней — от фундаментальных исследований (TRL 1) до проверенной системы в реальных условиях эксплуатации (TRL 9). Ключевым достоинством подхода является формализация критериев перехода между уровнями, что обеспечивает прозрачность принятия решений о финансировании и запуске.
Попытки адаптировать TRL для области ИИ и ML предпринимались неоднократно. De Bruin и коллеги [7] предложили AI Readiness Framework, ориентированный на оценку организационной зрелости в области ИИ. Однако данный подход сосредоточен на стратегическом уровне и не предоставляет операционных метрик для оценки конкретных ML-систем. Lavin и коллеги [8] ввели понятие Technology Readiness Levels for Machine Learning Systems, предложив девятиуровневую шкалу, однако не формализовали количественные критерии перехода и не рассмотрели аспекты мониторинга дрифта и операционной устойчивости.
1.2. Модели зрелости MLOps.
Microsoft предложила модель MLOps Maturity Model [4], включающую пять уровней — от отсутствия автоматизации (Level 0) до полной CI/CD/CT-автоматизации (Level 4). Google в работе Breck и коллег [5] представила ML Test Score — набор из 28 тестов, сгруппированных по категориям (данные, модель, инфраструктура, мониторинг). Оба подхода предоставляют ценные практические рекомендации, однако не объединены в единую формализованную шкалу с количественными порогами перехода.
Amershi и коллеги [9] провели крупномасштабное исследование практик ML-инженерии в Microsoft, выявив ключевые проблемы: управление качеством данных, воспроизводимость экспериментов и необходимость непрерывного мониторинга. Sculley и коллеги [10] в основополагающей работе «Hidden Technical Debt in Machine Learning Systems» систематизировали источники технического долга в ML-системах, включая проблемы зависимости данных, обратной связи и конфигурационного долга.
1.3. Проблема concept drift.
Concept drift — изменение статистических свойств целевой переменной, которую модель призвана предсказывать, с течением времени [11] — является одной из ключевых угроз стабильности ML-систем в промышленной эксплуатации. Gama и коллеги [12] предложили классификацию типов дрифта: внезапный (sudden), постепенный (gradual), инкрементальный (incremental) и рекуррентный (recurring). Lu и коллеги [13] представили обзор методов обнаружения дрифта, выделив статистические подходы (Page — Hinkley test, ADWIN), подходы на основе мониторинга производительности модели и подходы на основе анализа распределений входных признаков.
Для количественной оценки дрифта распределений широко применяются Population Stability Index (PSI) [14], дивергенция Кульбака — Лейблера (KL) [15] и тест Колмогорова — Смирнова (KS) [16]. Однако в научной литературе отсутствует комплексная методология, объединяющая различные статистические критерии и алгоритмические детекторы в единую систему принятия решений о переобучении модели с учётом корпоративных ограничений (стоимость переобучения, требования аудируемости, SLA).
Таким образом, анализ литературы позволяет выделить следующие лакуны: (1) отсутствие единой формализованной шкалы зрелости ML-систем с количественными критериями перехода; (2) недостаточная интеграция аспектов мониторинга дрифта в модели оценки production-readiness; (3) ограниченное количество эмпирических исследований применения фреймворков зрелости в реальных корпоративных проектах. Настоящая работа направлена на устранение указанных лакун.
2. Методология исследования
Исследование проведено с использованием комбинированной методологии, включающей:
— систематический анализ литературы (systematic literature review) для синтеза существующих подходов к оценке зрелости ML-систем [17];
— конструктивное исследование (design science research) [18] для разработки фреймворка PRL;
— практическую апробацию (case study) [19] для валидации фреймворка на реальных проектах.
Базой для эмпирической валидации послужили 37 проектов внедрения ML-систем, реализованных компанией Insight AI в период 2023–2025 гг. для корпоративных заказчиков в секторах финансов, ритейла, промышленности и телекоммуникаций. Проекты различались по масштабу (от отдельных ML-моделей до комплексных ИИ-платформ), типу задач (классификация, регрессия, рекомендательные системы, NLP, компьютерное зрение) и инфраструктурным требованиям (облачные, on-premise и гибридные развёртывания).
Для оценки эффективности фреймворка использовались следующие метрики: доля проектов, достигших промышленной эксплуатации (production deployment rate); среднее время от PoC до production (time-to-production, TTP); количество инцидентов деградации качества в первые 90 дней эксплуатации; уровень удовлетворённости заказчиков (NPS).
3. Фреймворк Production Readiness Level (PRL)
3.1. Архитектура фреймворка.
Предлагаемый фреймворк PRL представляет собой десятиуровневую шкалу оценки зрелости ML-систем, структурированную по четырём осям (dimensions): качество данных (Data Quality, DQ), качество модели (Model Quality, MQ), инфраструктурная готовность (Infrastructure Readiness, IR) и операционная устойчивость (Operational Resilience, OR). Каждый уровень PRL определяется набором обязательных критериев (quality gates) по каждой из четырёх осей, прохождение которых является необходимым условием для перехода на следующий уровень.
Общая формула определения уровня PRL системы:
PRL(S) = min(DQ(S), MQ(S), IR(S), OR(S)) (1)
где S — оцениваемая ML-система, а DQ, MQ, IR, OR — уровни зрелости по соответствующим осям. Принцип минимума отражает тот факт, что общая готовность системы ограничена наименее зрелым компонентом, аналогично «бутылочному горлышку» в теории ограничений [20].
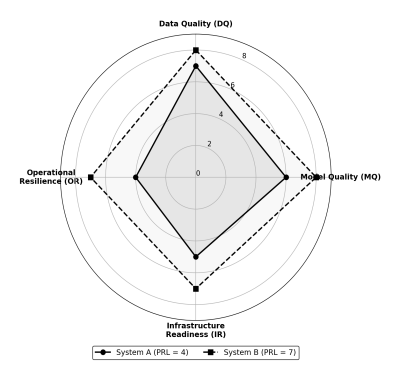
Рис. 1. Визуализация оценки PRL по четырём осям для двух ML-систем (System A — PRL 4, System B — PRL 7). Общий уровень PRL определяется минимальным значением по осям
3.2. Описание уровней PRL
Ниже приведена характеристика десяти уровней PRL с указанием ключевых критериев для каждой оси оценки (таблица 1).
Таблица 1
Шкала Production Readiness Level (PRL)
|
PRL |
Название уровня |
Data Quality (DQ) |
Model Quality (MQ) |
Infrastructure (IR) |
Operations (OR) |
|
0 |
Идея / Discovery |
Данные не исследованы |
Модель не определена |
Нет инфраструктуры |
Нет процессов |
|
1 |
Аудит данных |
EDA завершён, профиль данных задокумент |
Baseline определён |
Рабочее окружение |
Стейкхолдеры определены |
|
2 |
Data Pipeline |
Пайплайн подготовки данных автоматиз |
Эксперимент. окружение настроено |
Версионир. данных и кода |
KPI определены и согласов |
|
3 |
MVP модели |
Качество данных > порога |
MVP обучен, метрики > baseline |
CI для обучения |
Бизнес-метрики трекаются |
|
4 |
Пилот |
Data quality checks автоматиз |
A/B-тест проведён |
CI/CD pipeline |
HITL-процесс определён |
|
5 |
Pre-production |
Мониторинг дрифта вх. данных |
Модель валидир. на hold-out, shadow mode |
Staging-среда развёрнута |
SLA/SLO определены |
|
6 |
Production (ограниченный) |
Drift alerts настроены |
Canary/blue-green deploy |
Rollback автоматизир |
Incident response план |
|
7 |
Production (полный) |
Автоматич. retrain pipeline |
Champion/ Challenger |
Auto-scaling, fault tolerance |
Операц. runbook, on-call |
|
8 |
Оптимизация |
Feature store, data lineage |
Автоматич. подбор гиперпарам |
Cost optimization, GPU sharing |
Post-mortem процесс |
|
9 |
Непрерывная эволюция |
Автоматич. обнаруж. новых признаков |
Self-healing pipeline |
Multi-region, DR-план |
Непрерыв. аудит, compliance |
Каждый уровень PRL содержит чёткие критерии перехода (quality gates), которые формализованы через количественные пороговые значения и верифицируемые артефакты. Система следует принципу «fail-fast»: переход на следующий уровень невозможен без подтверждения выполнения всех обязательных критериев текущего уровня.
3.3. Система quality gates.
Quality gates (контрольные точки качества) представляют собой формализованные проверки, прохождение которых является обязательным условием для продвижения ML-системы на следующий уровень PRL. Каждый quality gate определяется четырьмя параметрами: (1) метрика — количественный показатель, подлежащий проверке; (2) пороговое значение — минимально допустимый уровень метрики; (3) метод верификации — способ проверки соответствия; (4) ответственный — роль, подтверждающая прохождение gate.
В таблице 2 представлены ключевые quality gates для перехода с уровня PRL 4 (Пилот) на уровень PRL 5 (Pre-production), так как именно этот переход является критическим барьером в большинстве корпоративных проектов.
Таблица 2
Quality gates для перехода PRL 4 → PRL 5
|
№ |
Quality Gate |
Метрика / Порог |
Метод верификации |
Ответственный |
|
QG-1 |
Полнота данных |
Missing rate < 5 % для critical features |
Автоматизир. проверка при ingestion |
Data Engineer |
|
QG-2 |
Целостность пайплайна |
100 % тестов пройдено |
CI/CD, unit + integration tests |
ML Engineer |
|
QG-3 |
Метрика модели |
Целевая > baseline + Δ (согласов.) |
Hold-out eval + A/B-тест |
Data Scientist |
|
QG-4 |
Латентность |
P99 < SLO (напр. 200 мс) |
Нагрузочное тестирование |
DevOps Engineer |
|
QG-5 |
Аудируемость |
Model card заполнена, lineage документир |
Ревью документации |
ML Tech Lead |
|
QG-6 |
Fairness / Bias |
Disparate impact < 0.2 для защищ. групп |
Bias audit report |
Data Scientist + Product |
|
QG-7 |
Shadow mode |
≥ 14 дней без аномалий |
Сравнение shadow vs production |
ML Tech Lead |
4. Методология мониторинга дрифта
Мониторинг дрифта является критическим компонентом обеспечения операционной устойчивости ML-систем в промышленной эксплуатации. В рамках предлагаемого фреймворка PRL мы выделяем три типа дрифта, требующих различных подходов к обнаружению и коррекции.
4.1. Классификация типов дрифта.
В контексте промышленных ML-систем мы выделяем следующие типы дрифта:
- Дрифт входных данных (data drift, covariate shift) — изменение распределения входных признаков P(X), при неизменном отображении P(Y|X). Пример: изменение демографического профиля пользователей рекомендательной системы в результате маркетинговой кампании.
- Дрифт концепта (concept drift) — изменение условного распределения P(Y|X), то есть изменение самой зависимости между признаками и целевой переменной. Пример: изменение паттернов потребления в ресторанной сети в результате макроэкономических факторов.
- Дрифт метки (label drift, prior probability shift) — изменение распределения целевой переменной P(Y) при неизменном P(Y|X). Пример: изменение доли положительных примеров в задаче классификации оттока клиентов.
4.2. Метрики обнаружения дрифта.
Для каждого типа дрифта предлагается набор статистических метрик с обоснованием пороговых значений (таблица 3).
Таблица 3
Метрики обнаружения дрифта и пороговые значения
|
Метрика |
Описание |
Warning порог |
Critical порог |
Тип дрифта |
|
PSI |
Population Stability Index |
0.1 |
0.25 |
Data drift |
|
KL-дивергенция |
Кульбак — Лейблер |
0.05 |
0.1 |
Data drift |
|
KS-тест |
Колмогоров — Смирнов (p-value) |
< 0.05 |
< 0.01 |
Data drift |
|
ADWIN |
Adaptive Windowing (δ) |
δ = 0.01 |
δ = 0.002 |
Concept drift |
|
Page — Hinkley |
Кумул. отклонение от среднего |
λ = 50 |
λ = 100 |
Concept drift |
|
Performance Δ |
Деградация целевой метрики |
> 5 % от SLO |
> 15 % от SLO |
Все типы |
4.3. Алгоритм принятия решений о переобучении
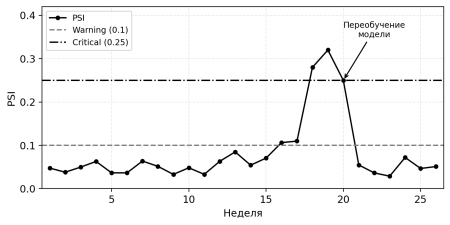
Рис. 2. Динамика метрики PSI по неделям для промышленной ML-системы. Пунктирные линии — пороги warning (0.1) и critical (0.25). Стрелкой отмечен момент переобучения модели, после которого PSI возвращается к нормальным значениям
На основе описанных метрик предлагается формализованный алгоритм принятия решений о переобучении модели. Алгоритм реализует двухуровневую систему порогов (warning / critical) и учитывает корпоративные ограничения:
Шаг 1. Непрерывный мониторинг: для каждого входного признака и целевой метрики модели вычисляются метрики дрифта на скользящем окне (рекомендуемый размер окна — 7 дней для высокочастотных систем, 30 дней для систем с низкой частотой обновления).
Шаг 2. Классификация алерта: при превышении порога warning по любой из метрик формируется предупреждение. При превышении порога critical формируется инцидент. Для снижения ложноположительных срабатываний применяется правило консенсуса: инцидент эскалируется только при одновременном превышении critical-порога по двум или более метрикам.
Шаг 3. Оценка влияния: при возникновении инцидента оценивается влияние дрифта на бизнес-метрики. Если деградация целевой бизнес-метрики превышает согласованный порог (определяется на этапе SLA/SLO), инициируется процедура переобучения.
Шаг 4. Переобучение и валидация: запуск автоматизированного пайплайна переобучения с обязательной валидацией новой модели на hold-out наборе и shadow deployment перед заменой текущей модели в production. Применяется паттерн champion/challenger: новая модель (challenger) должна превосходить текущую (champion) по целевой метрике с заданным уровнем статистической значимости (p < 0.05).
Формально условие замены модели может быть записано следующим образом:
Replace(Mchampion, Mchallenger) ⟺ Metric(Mchallenger) > Metric(Mchampion) ∧ p < α (2)
где α — уровень значимости (обычно 0.05), а p — p-value статистического теста сравнения метрик моделей.
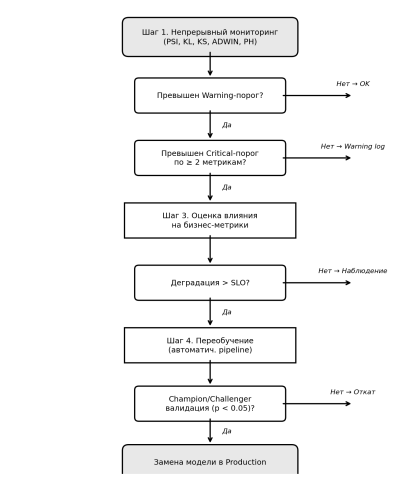
Рис. 3. Блок-схема алгоритма принятия решений о переобучении модели при обнаружении дрифта
5. Эмпирическая валидация фреймворка
5.1. Описание контекста и выборки.
Практическая апробация фреймворка PRL проведена на базе проектов компании Insight AI — продуктово-инженерной компании, специализирующейся на разработке и внедрении ИИ-систем для корпоративных заказчиков. В выборку вошли 37 проектов, реализованных в период 2023–2025 гг. Распределение проектов по отраслям: финансы — 10 (27 %), ритейл/HoReCa — 9 (24 %), промышленность — 8 (22 %), телекоммуникации — 6 (16 %), другие — 4 (11 %). Распределение по типу ML-задач: классификация — 12 (32 %), регрессия/прогнозирование — 8 (22 %), рекомендательные системы — 7 (19 %), NLP — 6 (16 %), компьютерное зрение — 4 (11 %).
5.2. Дизайн исследования.
Для оценки эффективности фреймворка использовалась квазиэкспериментальная схема: первые 15 проектов (реализованных до внедрения PRL) составили контрольную группу (baseline), оставшиеся 22 проекта (реализованных с применением PRL) — экспериментальную группу. Сравнение проводилось по четырём ключевым метрикам.
Таблица 4
Сравнительные результаты до и после внедрения PRL
|
Метрика |
Без PRL (n=15) |
С PRL (n=22) |
Δ |
|
Production deployment rate |
32 % (5 из 15) |
78 % (17 из 22) |
+46 п.п |
|
Median time-to-production (мес.) |
8.5 |
4.2 |
−51 % |
|
Инциденты деградации (90 дней) |
4.2 на проект |
1.1 на проект |
−74 % |
|
NPS заказчиков |
38 |
72 |
+34 |
5.3. Анализ результатов.
Наиболее значимым результатом является увеличение доли проектов, достигших промышленной эксплуатации, с 32 % до 78 % (рост на 46 процентных пунктов). Данный результат статистически значим (точный тест Фишера, p = 0.008). Медианное время от PoC до production сократилось с 8.5 до 4.2 месяцев (снижение на 51 %), что объясняется ранним выявлением инфраструктурных и организационных рисков на нижних уровнях PRL, а также стандартизацией артефактов и процессов.
Количество инцидентов деградации качества в первые 90 дней эксплуатации снизилось в 3.8 раза (с 4.2 до 1.1 на проект), что объясняется систематическим мониторингом дрифта и наличием автоматизированных процедур реагирования, внедрённых на уровнях PRL 5–7.
Рост NPS заказчиков с 38 до 72 указывает на повышение уровня удовлетворённости и доверия к ИИ-системам, что коррелирует с улучшением прозрачности процесса разработки и снижением числа «провальных» пилотов.
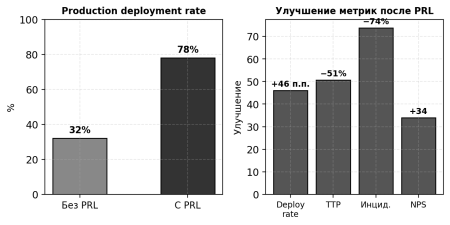
Рис. 4. Сравнение ключевых метрик до и после внедрения фреймворка PRL: (а) доля проектов, достигших production; (б) совокупное улучшение по четырём метрикам
5.4. Анализ типичных точек провала.
Анализ проектов, не достигших промышленной эксплуатации, позволил выявить наиболее частые уровни PRL, на которых происходило «застревание» проектов (таблица 5).
Таблица 5
Распределение проектов по уровням «застревания» (экспериментальная группа)
|
Уровень PRL |
Кол-во проектов |
Доля |
Типичная причина |
|
PRL 2 |
1 |
20 % |
Недостаточное качество исходных данных |
|
PRL 3 |
1 |
20 % |
Метрика модели не превысила baseline |
|
PRL 4 |
2 |
40 % |
Организационные барьеры (отсутствие ownership) |
|
PRL 5 |
1 |
20 % |
Инфраструктурные ограничения (closed contour) |
Как видно из таблицы 5, наиболее частой причиной «застревания» является переход PRL 4 → PRL 5 (от пилота к pre-production), что подтверждает критическую значимость quality gates, разработанных для данного перехода (см. таблицу 2). Примечательно, что 40 % провалов связаны не с техническими, а с организационными факторами (отсутствие бизнес-ownership, невозможность согласования SLA), что подчёркивает необходимость включения операционной оси (OR) в фреймворк оценки.
6. Обсуждение результатов
Предложенный фреймворк PRL обладает рядом преимуществ перед существующими подходами. Во-первых, в отличие от модели MLOps Maturity (Microsoft) [4], которая оценивает зрелость организации в целом, PRL оценивает зрелость конкретной ML-системы, что позволяет применять различные стратегии для проектов с разным уровнем готовности в рамках одной организации. Во-вторых, в отличие от ML Test Score (Google) [5], который представляет набор бинарных тестов, PRL предоставляет упорядоченную шкалу с чёткими переходами, что упрощает коммуникацию с бизнес-стейкхолдерами и планирование ресурсов.
Интеграция мониторинга дрифта непосредственно в шкалу зрелости (уровни PRL 5–7) является, по мнению автора, концептуальным вкладом работы, поскольку существующие фреймворки рассматривают мониторинг как отдельную активность, не связанную с оценкой готовности системы к эксплуатации.
Вместе с тем необходимо отметить ограничения исследования. Выборка из 37 проектов, реализованных одной компанией, не позволяет утверждать универсальную применимость фреймворка. Квазиэкспериментальный дизайн (сравнение «до» и «после» без рандомизации) не исключает влияния конфаундеров (рост зрелости команды, изменение типа проектов). Пороговые значения метрик дрифта (таблица 3) калиброваны на основе практического опыта и опубликованных рекомендаций, однако могут требовать адаптации для специфических доменов.
Перспективными направлениями дальнейших исследований являются: (1) валидация фреймворка на более широкой выборке проектов и организаций; (2) разработка автоматизированного инструмента (toolkit) для оценки PRL; (3) исследование корреляции уровня PRL с долгосрочной операционной устойчивостью ML-систем (> 12 месяцев); (4) адаптация фреймворка для генеративных ИИ-систем (LLM) и мультимодальных моделей, где проблемы дрифта и качества данных проявляются иначе.
Отдельного обсуждения заслуживает вопрос применимости фреймворка в условиях закрытого контура (closed contour) — архитектурного ограничения, типичного для ряда корпоративных заказчиков в секторах финансов, государственного управления и оборонной промышленности. В подобных условиях возможности облачных MLOps-платформ существенно ограничены, что повышает значимость локальных (on-premise) решений для мониторинга дрифта и автоматизации переобучения. Опыт автора показывает, что в проектах с закрытым контуром среднее время достижения PRL 6 увеличивается на 40–60 % по сравнению с облачными развёртываниями, что требует более раннего планирования инфраструктурных компонентов (начиная с PRL 2).
Также следует отметить, что фреймворк PRL может быть интегрирован с существующими корпоративными процессами управления проектами и рисками. В частности, уровни PRL могут быть включены в stage-gate модели управления проектами (Cooper, 2008), где каждый gate принятия решения о продолжении проекта дополняется требованием достижения определённого уровня PRL. Это позволяет существенно повысить качество решений об инвестициях в ML-проекты на ранних стадиях и снизить объём «утопленных затрат» (sunk costs) при своевременной остановке бесперспективных инициатив.
Наконец, важно подчеркнуть культурный аспект внедрения фреймворка. Переход от «науки ради науки» (data science as research) к «инженерии ради результата» (data science as engineering discipline) требует изменения ментальных моделей как со стороны команд Data Science, так и со стороны бизнес-заказчиков. Фреймворк PRL, формализуя критерии готовности через измеримые показатели, способствует формированию общего языка между техническими и бизнес-стейкхолдерами, что является необходимым условием успешного масштабирования ML-инициатив в корпоративном контексте.
7. Практические рекомендации по внедрению фреймворка PRL
На основе опыта практической апробации фреймворка PRL в 37 проектах автор формулирует ряд рекомендаций для организаций, планирующих его внедрение.
7.1. Организационные предпосылки.
Эффективное внедрение фреймворка PRL требует наличия ряда организационных предпосылок. Прежде всего, необходимо формирование кросс-функциональной команды (ML-инженеры, DevOps, продуктовые менеджеры, представители бизнеса), разделяющей ответственность за прохождение quality gates. Практика показала, что назначение единого «владельца PRL» (PRL Owner) — роли, координирующей оценку зрелости и обеспечивающей прозрачность для стейкхолдеров — существенно повышает эффективность процесса. В проектах с назначенным PRL Owner медианное время достижения PRL 6 составило 3.8 месяца, тогда как в проектах без выделенной роли — 6.1 месяца.
Вторым важным условием является наличие инфраструктуры для автоматизированного вычисления метрик PRL. Ручная оценка качества данных, производительности модели и показателей дрифта не масштабируется и создаёт риски субъективности. Рекомендуется создание централизованного дашборда (PRL Dashboard), агрегирующего метрики по всем четырём осям в реальном времени и визуализирующего текущий уровень PRL каждой системы.
7.2. Поэтапная стратегия внедрения.
Рекомендуется поэтапное внедрение фреймворка, начиная с наиболее критичных проектов. На первом этапе (1–2 месяца) проводится калибровка: пороговые значения quality gates адаптируются под специфику организации и домена. На втором этапе (2–4 месяца) фреймворк применяется к 2–3 пилотным проектам с целью сбора обратной связи и доработки процессов. На третьем этапе (4–6 месяцев) PRL становится обязательным элементом жизненного цикла всех ML-проектов организации.
Важно подчеркнуть, что фреймворк PRL не является бюрократическим барьером, замедляющим разработку. Напротив, раннее выявление проблем (на уровнях PRL 1–3) позволяет избежать дорогостоящих неудач на поздних стадиях. Аналогия с «пирамидой тестирования» в программной инженерии [21] уместна: стоимость устранения дефекта растёт экспоненциально с каждой стадией, на которой он обнаруживается.
7.3. Адаптация для различных типов ML-задач.
Пороговые значения quality gates могут варьироваться в зависимости от типа ML-задачи и доменной специфики. Для систем реального времени (рекомендательные системы, fraud detection) критичны метрики латентности и отказоустойчивости, тогда как для пакетных систем (monthly forecasting, batch scoring) более значимы метрики воспроизводимости и аудируемости. В регулируемых отраслях (финансы, здравоохранение) ось операционной устойчивости (OR) требует дополнительных проверок на соответствие нормативным требованиям (compliance checks).
Для систем на основе больших языковых моделей (LLM) фреймворк требует расширения с учётом специфических рисков: галлюцинации, утечка конфиденциальной информации, нестабильность генерации. В этом случае ось качества модели (MQ) должна включать метрики оценки фактологической точности, токсичности и соответствия инструкциям, а мониторинг дрифта — охватывать не только статистические свойства входных данных, но и семантические характеристики генерируемых ответов.
7.4. Экономическая обоснованность.
Внедрение фреймворка PRL сопряжено с определёнными затратами: разработка и поддержка PRL Dashboard, обучение команды, трудозатраты на проведение ревью quality gates. По оценкам автора, накладные расходы составляют 8–12 % от общего бюджета ML-проекта. Однако экономический эффект значительно превышает затраты: сокращение доли провальных проектов (с 68 % до 22 %) и снижение time-to-production (с 8.5 до 4.2 месяцев) приводят к существенной экономии ресурсов. При средней стоимости ML-проекта в 5–15 млн рублей потери от неудачных пилотов могут составлять десятки миллионов рублей в год для крупной организации.
Заключение
В настоящей работе представлен оригинальный фреймворк оценки готовности систем машинного обучения к промышленной эксплуатации — Production Readiness Level (PRL). Фреймворк формализует процесс перехода ML-системы от идеи до промышленной эксплуатации через десятиуровневую шкалу зрелости, структурированную по четырём осям: качество данных, качество модели, инфраструктурная готовность и операционная устойчивость.
Ключевые результаты исследования:
- Разработана десятиуровневая шкала PRL с количественными критериями перехода (quality gates), обеспечивающая прозрачность и воспроизводимость оценки готовности ML-систем.
- Предложена комплексная методология мониторинга дрифта, интегрирующая статистические критерии (PSI, KL-дивергенция, KS-тест) и алгоритмические детекторы (ADWIN, Page — Hinkley) в единую систему принятия решений о переобучении.
- Практическая апробация на 37 реальных проектах подтвердила эффективность фреймворка: доля проектов, достигших промышленной эксплуатации, выросла с 32 % до 78 %, медианное время до production сократилось на 51 %, количество инцидентов деградации снизилось в 3.8 раза.
Результаты исследования могут быть использованы руководителями подразделений Data Science, ML-инженерами и архитекторами ИИ-решений для систематизации процессов внедрения ML-систем в корпоративном контексте, снижения доли «пилотных ловушек» и повышения операционной устойчивости ИИ-решений в промышленной эксплуатации.
Литература:
- McKinsey & Company. The state of AI in early 2024: Gen AI adoption spikes and starts to generate value. — McKinsey Global Survey, 2024. — URL: https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai (дата обращения: 15.01.2026).
- Gartner, Inc. Predicts 2022: AI Development Life Cycle Optimization Drives Value from AI. — Gartner Research, 2022. — 28 с.
- Paleyes, A., Urma, R.-G., Lawrence, N. D. Challenges in Deploying Machine Learning: a Survey of Case Studies // ACM Computing Surveys. — 2022. — Vol. 55, № 6. — С. 1–29.
- Microsoft. MLOps Maturity Model. — Microsoft Azure Documentation, 2023. — URL: https://learn.microsoft.com/en-us/azure/architecture/ai-ml/guide/mlops-maturity-model (дата обращения: 15.01.2026).
- Breck, E., Cai, S., Nielsen, E., Salib, M., Sculley, D. The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction // Proceedings of IEEE Big Data. — 2017. — С. 1123–1132.
- Mankins, J. C. Technology readiness levels: A white paper. — NASA, 1995. — 5 с.
- De Bruin, T., Rosemann, M., Freeze, R., Kulkarni, U. Understanding the main phases of developing a maturity assessment model // Proceedings of ACIS. — 2005. — С. 8–19.
- Lavin, A., Gilligan-Lee, C. M., Visber, A. et al. Technology Readiness Levels for Machine Learning Systems // Nature Communications. — 2022. — Vol. 13, № 1. — Art. 6039.
- Amershi, S., Begel, A., Bird, C. et al. Software Engineering for Machine Learning: A Case Study // Proceedings of IEEE/ACM ICSE-SEIP. — 2019. — С. 291–300.
- Sculley, D., Holt, G., Golovin, D. et al. Hidden Technical Debt in Machine Learning Systems // Proceedings of NeurIPS. — 2015. — С. 2503–2511.
- Widmer, G., Kubat, M. Learning in the presence of concept drift and hidden contexts // Machine Learning. — 1996. — Vol. 23, № 1. — С. 69–101.
- Gama, J., Žliobaitė, I., Bifet, A., Pechenizkiy, M., Bouchachia, A. A survey on concept drift adaptation // ACM Computing Surveys. — 2014. — Vol. 46, № 4. — С. 1–37.
- Lu, J., Liu, A., Dong, F., Gu, F., Gama, J., Zhang, G. Learning under Concept Drift: A Review // IEEE Transactions on Knowledge and Data Engineering. — 2019. — Vol. 31, № 12. — С. 2346–2363.
- Yurdakul, B. Statistical Properties of Population Stability Index // Journal of Model Risk Validation. — 2023. — Vol. 15, № 3. — С. 45–62.
- Kullback, S., Leibler, R. A. On Information and Sufficiency // The Annals of Mathematical Statistics. — 1951. — Vol. 22, № 1. — С. 79–86.
- Massey, F. J. The Kolmogorov-Smirnov Test for Goodness of Fit // Journal of the American Statistical Association. — 1951. — Vol. 46, № 253. — С. 68–78.
- Kitchenham, B. Procedures for Performing Systematic Reviews. — Keele University Technical Report TR/SE-0401. — 2004. — 33 с.
- Hevner, A. R., March, S. T., Park, J., Ram, S. Design Science in Information Systems Research // MIS Quarterly. — 2004. — Vol. 28, № 1. — С. 75–105.
- Yin, R. K. Case Study Research: Design and Methods. — 5th ed. — SAGE Publications, 2014. — 282 с.
- Goldratt, E. M. Theory of Constraints. — North River Press, 1999. — 162 с.
- Boehm, B. W., Papaccio, P. N. Understanding and Controlling Software Costs // IEEE Transactions on Software Engineering. — 1988. — Vol. 14, № 10. — С. 1462–1477.

