





Приводится описание процесса разработки сервиса по распознаванию брендовых лейблов для большой базы логотипов с использованием алгоритмов компьютерного зрения. Демонстрируется производительность разработанного подхода над другими методами компьютерного зрения.
Ключевые слова: алгоритм распознавания брендовых лейблов, классификация объектов на изображении, распознавание на большой базе графических объектов, анализ эффективности метода SIFT.
Обозначения и сокращения
BOW Bag of words [1]
SIFT Scale-invariant feature transform [2]
ORB Oriented FAST and Rotated BRIEF [3]
pHash Perceptual hash [4]
ВВЕДЕНИЕ
В настоящий момент в мире существует огромное количество брендовых лейблов. Бренды окружают нас повсюду. Можно заметить, что иногда люди начинают общаться в терминах логотипов для конкретизации места встречи, составления маршрута на выходные. Бренды хорошо запоминаются и используются людьми в качестве выражения мысли, становятся предметами обсуждения, что совсем неудивительно. Современное общество давно научилось жить в гармонии с информацией вокруг: рекламные ролики, щиты, плакаты, радио, одежда, техника, автомобили и многое другое — все пропагандирует уникальную символику, с которой мы сталкиваемся каждый день.
Создание системы распознавания брендовых лейблов решило бы множество проблем по автоматизации: классификации, поиска и анализа логотипов на изображениях и видеопоследовательностях.
Такая система найдет применение в различных областях:
а) Устранение рекламных логотипов с видеопоследовательности;
б) Геопозиционирование (Indoor навигация внутри торговых комплексов);
в) Решение проблем распознавания коммерческих (закрытых) лейблов;
г) Распознавание уникальных меток наподобие QR-кодов (может пригодиться в стартап сфере);
д) Таргетинговая реклама (на основании снимков одежды человека);
е) Электронный мерчандайзер (распознавание товара на полках в магазине для подачи сигналов о заканчивающемся товаре);
ж) Распознавание марок автомобилей (для различного рода классификации, например, спрос населения на определенные марки);
з) Контроль над интернет-рекламой (распознавание оплаченных показов баннеров);
и) Поиск кроп-дубликатов (вырезок из других изображений) для кластеризации в базе данных.
Изучив потенциальные области применения системы, были сформулированы основные цели и задачи работы.
Цели работы:
1) Разработать быстрый метод обнаружения и распознавания логотипов на изображении, инвариантный к повороту и масштабированию (100 мс на выборке из 100 логотипов);
2) Представить метод в виде сервиса распознавания брендовых лейблов;
3) Сравнить полученные результаты с существующими аналогами.
Задачи:
1) Изучить существующие подходы к распознаванию объектов на изображении;
2) Произвести обзор аналогов на рынке c целью синтеза методов, которые в них присутствуют;
3) На основании рассмотренных систем выявить сильные/слабые стороны используемых подходов;
4) Сформулировать методологию (комбинацию алгоритмов) для сервиса распознавания логотипов на большой базе данных в режиме реального времени.
На текущий момент по решению проблемы распознавания логотипов существует множество подходов. Все они описывают различные методы по решению данной проблемы, основным недостатком которых является потеря точности и скорости распознавания на большой выборке логотипов.
В данной работе описывается процесс разработки производительного, c точки зрения точности и скорости, сервиса распознавания брендовых лейблов, нацеленного на обработку большой базы логотипов (более 100), а также приводится анализ его эффективности и сравнение с аналогами.
Разработка сервиса
После анализа всех подходов по распознаванию брендовых лейблов на изображении было выявлено, что методы, основанные на сегментации, не подходят для выделения границ логотипов и часто на выходе дают ложный результат. Так были рассмотрены методы по кластеризации угловых точек, найденных методом Harris Corners [5], выделение контуров Canny [6], произведен поиск схожих областей на изображении по гистограмме (Bundle histogram matching [7]), с целью уточнения области логотипов. Наилучшим же подходом для поиска логотипа оказался Bag of words (BOW) — сумка слов, который изображен на рисунке 1.
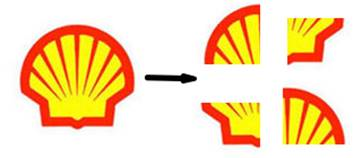
Рис. 1. Логотип Shell в представлении Bag of words
Сумка слов, в отличие от методов сегментации, предлагает представлять логотип как множество информационных кусочков, тем самым увеличивая шансы на распознавание. Так как в методе BOW вклад в объект вносит не цельный объект, а его фрагменты, то необходимо и достаточно найти некоторое количество кусочков одного и того же логотипа, чтобы утверждать о его присутствии на изображении. Если же рассматривать методы сегментации, то часто приходится рассматривать полное совпадение всей картины объекта.
Рассматривая подход BOW, было решено найти оптимальный метод извлечения фрагментов из изображения. Классический подход, основанный на регулярной сетке, представленный на рисунке 2, нам не подходил, так как сервис должен уметь распознавать повернутые логотипы, что неприемлемо замедляет метод регулярной сетки, так как ее тоже приходится вращать для большого количества масштабов.

Рис. 2. Обнаружение объекта пирамидой регулярных сеток
Было решено осуществить поиск оптимального метода для определения на изображении устойчивых областей к распознаванию. Наиболее подходящим методом был выбран SIFT.
SIFT решает основную задачу за нас — он находит опорные точки, инвариантные к поворотам, масштабированию и переносу см. рисунок 3.

Рис. 3. Найденные опорные точки методом SIFT
Даже если изображения совсем не похожи по фактуре и цвету, на них найдутся схожие опорные точки.
Вся проблема метода SIFT и подобных ему методов заключается в падающей точности дескрипторов на большой базе логотипов, то есть при расширении базы с логотипами критично увеличивается количество ложных срабатываний дескрипторов, что продемонстрировано на рисунке 4.

Рис. 4. Ложные срабатывания метода SIFT на базе из 100 логотипов
Дескриптор может быть схож с десятками, а то и сотнями дескрипторов из различных моделей. Когда производились тесты, то было отчетливо видно, как логотипы «Puma» и «Adidas» по результатам распознавания дескрипторов давали примерно одинаковые результаты. «Puma» при отдалении логотипа от камеры становился «Adidas», и наоборот. При этом пространственное расположение опорных точек объекта оставалось стабильным при повороте и масштабировании.
К сожалению, это не единственный недостаток SIFT-подобных методов. Размерность дескрипторов для сравнения областей изображения обычно составляет от 32 до 128 чисел (в ускоренных вариантах это 32 целых числа — алгоритм ORB, в классическом SIFT дескрипторе 128 чисел с плавающей точкой) на одну опорную точку. Так как на изображение может приходиться в среднем до 10000 опорных точек, что обозначает 1280000 значений дескрипторов, сравнение таких дескрипторов на большой базе логотипов будет очень затратным. На 500 логотипах результат можно ждать десятки минут. Такие дескрипторы никак не подходят на сегодняшний день для распознавания в режиме реального времени. Поэтому было решено найти метод, который бы эффективно сжал информацию по дескриптору и при этом еще увеличил точность распознавания для исключения ложных срабатываний SIFT дескрипторов. Таким образом, идеальным случаем для нас является не 128 значений на одну опорную точку, а одно значение, которое бы характеризовало всю опорную точку и при этом содержало максимум информации для точной идентификации опорной точки в другом объекте.
После долгих поисков был найден метод, на котором и проводились все дальнейшие исследования и опыты в данной работе — это перцептуальный хэш (pHash). Перцептуальный хэш представляет из себя алгоритм отображения картинки в уникальное long число, которое будет схожим только в случае близких по содержанию изображений. Проведя эксперименты, оказалось, что pHash — очень точный метод, и хорошо работает для поиска схожих строгих изображений, которыми являются брендовые лейблы, так как их размеры и пропорции задаются жестко и регламентированы правообладателем. Перцептуальные хэши скорее не пропустят правильный результат, чем дадут ложный, в этом и есть их положительная особенность. В случае со строгим представлением логотипов эта особенность позволяет получить существенное преимущество над ложными срабатываниями. Также pHash подошел тем, что на выходе отдает одно long значение, которое затем легко и быстро можно сравнить со значением модели через расстояние Хэмминга (по экспериментам миллионы значений сравниваются за миллисекунды).
На протяжении исследования было выявлено, что pHash инвариантен относительно масштаба, так как любое изображение, идущее на вход алгоритма, сжимается до 32x32 пикселей. Таким образом, сразу отбрасывается проблема с сохранением пропорций исследуемого объекта изображения. После анализа формата SIFT и ORB дескрипторов была предпринята попытка улучшить их сжатие и провести анализ эффективности.
Оказалось, что ORB дескрипторы представлены в виде матрицы яркостей рассматриваемой области опорной точки и представляют собой 32 значения от 0 до 255. Такое представление схоже с форматом изображения в градациях серого, с которым работает pHash. Таким образом, 32 байта были представлены матрицей 16x16 бит, из которых pHash сформировал одно long число.
Такой подход дал существенный прирост в скорости, так как вместо тридцати двух чисел теперь достаточно сравнить одно в формате long.
Однако при таком подходе существенно увеличились ложные срабатывания, так как произошло сжатие данных. Из-за высокого прироста скорости было решено произвести еще некоторые улучшения по уточнению распознавания и включить в работу сервиса алгоритм проверки пространственного расположения точек найденного объекта и эталона, см. рисунок 5. Таким образом, была улучшена точность распознавания логотипов с большим масштабом. Если же логотип был маленького размера, то количества опорных точек не хватало для его точной идентификации, и так же в случае сравнения дескрипторов «Puma» и «Adidas» возникали ложные срабатывания.

Рис. 5. Сравнение ORB дескрипторов с фильтром пространственного расположения точек
После попыток сжатия классических дескрипторов опорных точек было решено отказаться от них. То есть от метода SIFT остался только метод определения опорных точек, дескрипторы не вычислялись.
Каждая опорная точка в методе SIFT имеет свой результирующий вектор, который говорит о том, на какой угол повернут фрагмент изображения в области опорной точки, а также характеризует радиус области изображения, для которого она вычислена.
Вспоминая свойство pHash, который сжимает изображения произвольного размера, не теряя в точности сравнения, и Bag of words модель, которая предлагает представлять изображение как множество составных кусочков, был реализован программный прототип, где в качестве «слов» из модели BOW выступала область опорной точки, с которой вырезалось изображение по прямоугольнику, соответствующему повороту (направлению) опорной точки и ее размеру (длине вектора). Результат данного подхода продемонстрирован на рисунке 6.

Рис. 6. Опорные точки SIFT с pHash дескриптором
Такой подход показал оптимальный результат в точности и скорости распознавания, но на большой базе логотипов продолжали возникать ложные срабатывания. Так как теперь вклад в опорную точку вносит вся область изображения, заданная опорной точкой, целесообразно пропорционально увеличить каждую опорную точку для повышения уникальности изображения, которое в нее входит, что изображено на рисунок 7. Тем самым уменьшить шанс на нахождение такого же кусочка в другом логотипе, см. рисунок 8. Опытным путем был выявлен оптимальный коэффициент vscale, равный трем, который используется для определения размерности опорной точки vsize = vscale * featurePointVectorSize.

Рис. 7. Логотип «Adidas» в торговом центре, распознаваемый pHash дескрипторами

Рис. 8. Демонстрация отсутствия ложных срабатываний
Этапы работы сервиса:
Резюмируя описанный процесс разработки и тестирования сервиса, можно выделить основные этапы работы системы:
1. Применение операторов увеличения резкости изображения;
2. Вычисление опорных точек методом SIFT см. рисунок 9;

Рис. 9. Вычисление опорных точек методом SIFT
3. Выделение фрагмента опорной точки в прямоугольную область, используя ее поворот и размерность см. рисунок 10;

Рис. 10. Выделение фрагментов в прямоугольную область
4. Вычисление pHash дескрипторов по фрагменту каждой опорной точки см. рисунок 11;

Рис. 11. Фрагменты изображения, и посчитанные для них перцептуальные хэши
5. Сравнение найденных дескрипторов с базой дескрипторов pHash для каждого логотипа см. рисунок 12;

Рис. 12. Представление изображения в области опорной точки в виде pHash значения
6. Исследование количества совпавших фрагментов логотипа для вывода информации об обнаружении.
Анализ эффективности
Основываясь на многочисленных экспериментах, был сделан вывод о том, что задача классификации изображения, основанная на выделении опорных точек и сравнении соответствующих гистограмм, не дает приемлемой точности распознавания на изображениях реального мира. Алгоритм Bundle Histogram Matching (сравнение близких областей по гистограмме) дает значительные сбои и захватывает дополнительные участки изображения (кроме логотипа) в 60 % случаев см. таблица 1. Такие результаты нельзя считать достоверными. Поэтому в рамках моей магистерской диссертации, были изучены новые техники по распознаванию логотипов на изображении, в том числе методы SIFT, ORB, BOW и pHash. На основании опытных исследований была выявлена оптимальная точность распознавания логотипов 90 % на базе в 100 логотипов, см. таблица 2. Тесты проводились на различного рода изображениях при стабильной скорости, приемлемой для частоты кадра 20 кадр/c. Такой результат получился в комбинации ключевых точек SIFT с использованием отпечатков pHash в качестве дескрипторов.
В результате был получен точный метод нахождения логотипов на изображении с минимальным количеством ложных срабатываний и высокой скоростью распознавания.
Все тесты производительности проводились на тестовом персональном компьютере, характеристики которого приведены в лит.обзоре. Изображения, содержащие брендовый лейбл, заимствовались как из сети Интернет, так и фиксировались на камеру в торговых центрах.
Разработанный сервис устойчив к повороту, масштабированию логотипов, а также может справиться с небольшой перспективой.
Пример распознавания фрагментов приведен на рисунке 13.

Рис. 13. Идентифицированные фрагменты логотипа Starbucks
Таблица 1
Тестирование производительности методов распознавания логотипов
|
Кол-во логотипов |
SIFT & pHash Descriptors |
Orb & Classic Descriptors |
SIFT & Classic Descriptors |
Segmentation & Keypoint Cluster |
Bundle Histogram Matching Segm |
|
10 шт |
1 мс |
70 мс |
131 мс |
60 мс |
70 мс |
|
50 шт |
40 мс |
270 мс |
622 мс |
90 мс |
100 мс |
|
100 шт |
100 мс |
600 мс |
1218 мс |
140 мс |
150 мс |
Резюмируя скорость сравнения дескрипторов, указанную в таблице 2, можно сделать вывод, что алгоритм поиска фрагментов дает наилучший результат в скорости в случае pHash дескрипторов, так как использование перцептуальных хэшей дало возможность сильно сократить размерность сравниваемых данных фрагмента до одного long числа. Если рассмотреть график на рисунке 14, то можно увидеть, что временные затраты на распознавание при возрастании числа логотипов в базе медленнее всего растут в предложенном методе.
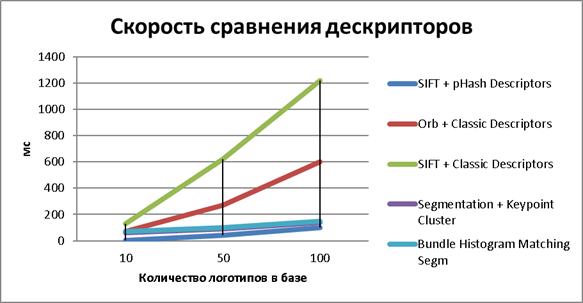
Рис. 14. Тестирование производительности методов распознавания логотипов
Резюмируя проценты удачных распознаваний логотипов, указанных в таблице 3 и на графике представленном на рисунке 15, можно сказать, что наилучший результат при возрастании количества логотипов в базе дают также pHash дескрипторы. Это связано с тем, что алгоритм pHash строит строгий отпечаток изображения и при малом расстоянии Хэмминга a <= 2 не пропускает ложные срабатывания. Так как логотипы имеют строгую форму, они с большим шансом пройдут проверку и будут пропущены.
Таблица 2
Анализ точности распознавания
|
Кол-во логотипов |
SIFT & pHash Descriptors |
Orb & Classic Descriptors |
SIFT & Classic Descriptors |
Segmentation & Keypoint Cluster |
Bundle Histogram Matching Segm |
|
10 шт |
100 % |
90 % |
100 % |
50 % |
60 % |
|
50 шт |
95 % |
80 % |
90 % |
40 % |
50 % |
|
100 шт |
93 % |
70 % |
80 % |
30 % |
45 % |
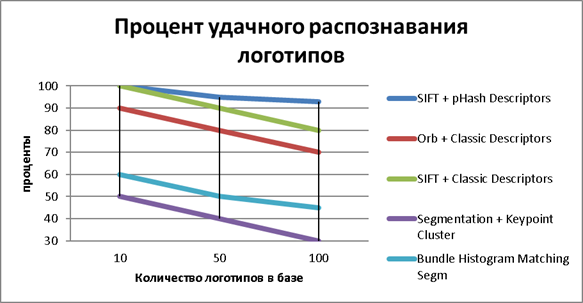
Рис. 15. Анализ точности распознавания
В общем случае pHash дескриптор способен проверить идентичность картинки, даже если на нее была нанесена небольшая копирайт метка. Перцептуальные хэши нечувствительны к цвету, контрастности, яркости, размеру и даже к слабым геометрическим изменениям, из-за чего и были использованы в данной работе.
Высокая точность pHash дескрипторов достигается за счет того, что в формирование хэша вносит вклад каждый пиксель картинки.
ЗАКЛЮЧЕНИЕ
В рамках данной работы мною был разработан сервис для обнаружения и распознавания логотипов на изображении, который показал высокую скорость распознавания 100 мс (на базе из 100 логотипов) при точности 93 %.
Были изучены существующие подходы к распознаванию объектов на изображении в реальном времени и проведены тесты производительности наиболее популярных методов в задачах поиска дубликатов в изображении.
На основании рассмотренных систем был выявлен точный метод нахождения опорных точек изображения SIFT. Был разработан новый подход к вычислению дескриптора опорной точки с использованием алгоритма перцептуальных хэшей, за счет чего была достигнута высокая точность распознавания при высокой производительности по сравнению с классическими дескрипторами.
Система тестировалась на заранее собранной выборке из 100 логотипов и прошла проверку.
Эксперименты показывают стабильные результаты вместе с точной классификацией логотипов. Брендовые лейблы со сложными изображениями фона или испорченные (погнутые, закрытые, повернутые) также могут быть распознанными. Система является платформой для дальнейших разработок, но уже может применяться в реальных условиях, для которых и создавалась, может позиционироваться как система для поиска логотипов на изображении.
Литература:
1. Алгоритмы класса bag of words [Электронный ресурс] URL: http://www.intuit.ru/studies/courses/10621/1105/lecture/17983?page=3
2. Ethan Rublee, Vincent Rabaud, Kurt Konolige, Gary R. Bradski: ORB: An efficient alternative to SIFT or SURF. ICCV 2011: 2564–2571.
3. (ORB) Oriented FAST Rotated BRIEF [Электронный ресурс] URL: http://www.en.wikipedia.org/wiki/Orb
4. Открытая библиотека по работе с перцептуальными хэшами [Электронный ресурс] URL: http://www.phash.org/
5. Corner detection [Электронный ресурс] URL: en.wikipedia.org/wiki/Corner_detection
6. Оператор Кэнни [Электронный ресурс] URL: http://www.ru.wikipedia.org/wiki/Оператор_Кэнни
7. Histogram matching [Электронный ресурс] URL: http://www.paulbourke.net/texture_colour/equalisation/
