Introduction
Autonomous multi-agent coordination has become a defining engineering constraint as deployment scales have grown from isolated laboratory demonstrations to production systems involving hundreds of concurrently active agents sharing physical infrastructure. Manufacturing cells, urban vehicle fleets, and logistics warehouses now operate at densities where the choice of coordination architecture directly shapes throughput, safety margins, and system behavior under hardware failures or communication disruptions. Centralized orchestration dominated early deployments because it offered tractable optimization and straightforward consistency guarantees (Stone & Veloso, 2000; Jennings, 1993). At the agent scales now common in industrial practice, however, the structural costs of a hub-and-spoke topology have become a primary engineering concern rather than a secondary consideration.
The costs take three forms. Agent-to-controller round-trip latency compounds with global planning computation as fleet size grows; reported values in centralized vehicle coordination platforms range from 150 ms to over 400 ms under moderate conflict rates (Dresner & Stone, 2008; Zhong et al., 2023, pp. 6325–6326), which exceed the sub-100 ms ceiling of close-formation platoon control and the sub-50 ms ceiling of high-speed manufacturing cell sequencing. The controller also constitutes a single point of failure whose disruption eliminates coordination for all connected agents simultaneously, rather than degrading it gradually (Lynch, 1996; Tanenbaum & Van Steen, 2007). Global state consistency maintenance scales with agent population and its communication cost grows without bound in geographically distributed deployments (Fischer et al., 1985; Gilbert & Lynch, 2002).
Fully decentralized architectures resolve the latency and resilience problems but cannot sustain the coordination quality required in high-density domains where agents contend continuously for shared resources (Parker, 1998; Cao et al., 1997). Among hybrid approaches, DANCeRS (Patwardhan & Davison, 2025, preprint) addresses distributed consensus through zone-partitioned leader election but provides no predictive pre-computation, leaving decision latency bounded by reactive inference time. Neurosymbolic planning systems deliver constraint-guaranteed policies but depend on centralized planners for vocabulary maintenance (Garcez & Lamb, 2023). Fault-tolerant distributed architectures in the multi-robot literature characterize degradation empirically without specifying per-tier bounds in advance (Pierson & Schwager, 2018; Farinelli et al., 2004). Because no published design jointly addresses all three gaps, deployed systems currently absorb significant performance loss along whichever dimension is deprioritized. The Distributed AI Decision Engine presented here closes all three gaps through specific architectural mechanisms, evaluates performance against a cloud-centralized reference under nominal and degraded conditions, and specifies operationally verifiable bounds for its three-tier fault-tolerance model.
Methods
Each physical or logical agent instantiates exactly one Decision Agent Node (DAN). The live population of active DANs constitutes the engine's membership, managed by a Membership and Topology Management (MTM) subsystem executing a modified Gossip protocol (Karp et al., 2000) that records per-peer one-way communication latency, packet-loss rate as a rolling 30-sample mean, and an aggregate link-quality score for each neighbor. The neighborhood radius was set to 3 hops in all reported experiments. A mesh topology is a structural precondition for the two-round-trip termination of conflict resolution: edge-local arbitration requires direct peer-to-peer channels, and routing through aggregation points would reintroduce the controller-hop overhead the design is intended to eliminate.
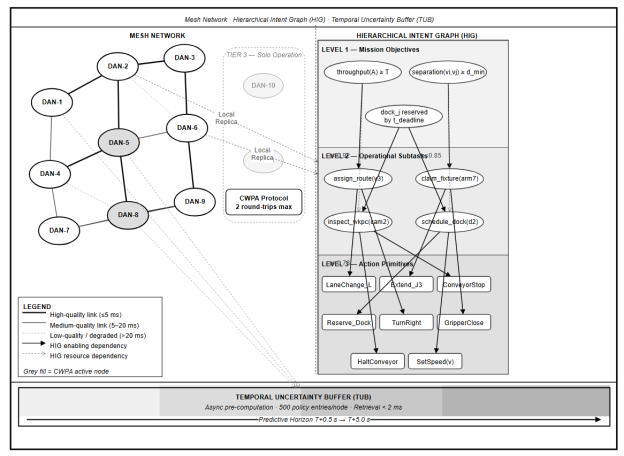
Fig. 1. System-Level Architecture
The Sensor Interface Layer normalizes inputs from LIDAR point clouds, RGB-D camera frames, inertial measurement unit streams, and industrial encoder pulses into Observation Vectors aligned to a common IEEE 1588 Precision Time Protocol clock reference. Temporal alignment is a strict requirement because proposals from nodes referencing different observation instants would carry systematically inconsistent confidence scores, distorting arbitration outcomes.
The Contextual State Memory (CSM) maintains a rolling 2-second window of Observation Vectors and compresses it through a gated recurrent neural network into a fixed-dimensional State Embedding. The gated recurrent design is preferable to Transformer-based alternatives here because its per-timestep computational cost is independent of sequence length. Transformer architectures scale quadratically with window width, which precludes deterministic latency on embedded processors with constrained memory bandwidth.
The Local Inference Module (LIM) takes the State Embedding and the local HIG replica as joint input. A neural policy network scores the action primitive vocabulary, producing a softmax probability distribution; the score assigned to each candidate is its softmax probability α . A symbolic constraint evaluator then removes any candidate associated with a safety constraint violation, resource exclusivity conflict, or operational prohibition in the node's current constraint vocabulary. The filtering produces a Boolean accept/reject decision with a traceable audit record for each candidate. Constraint violations are structurally excluded with respect to the explicitly specified vocabulary; incomplete initial specification remains a residual risk, which the HIG cryptographic delta verification addresses by preventing unauthorized post-deployment vocabulary modification.
Each DAN requires a sustained neural inference throughput of at least 4 TOPS to execute the LIM, TUB predictive model, and CWPA simultaneously within nominal latency bounds. On hardware delivering below this threshold, the LIM may be configured in symbolic-only mode, omitting the neural policy network at the cost of adaptivity to environmental patterns not explicitly represented in the constraint set.
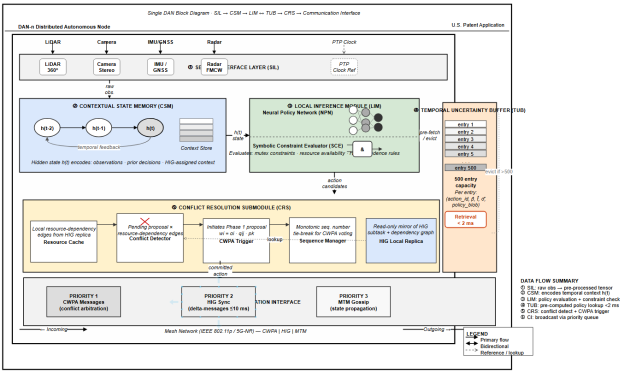
Fig. 2. DAN Internal Architecture
The Conflict Resolution Submodule (CRS) monitors pending action proposals through the CWPA broadcast channel and maintains a resource-to-claimant cache. Proposals claiming no contested resource bypass Phases 3–5 of the CWPA and proceed directly to Phase 6. Under nominal conditions, where most actions do not involve contested resources, this bypass is the dominant contributor to the engine's low median latency.
The CWPA resolves inter-node conflicts within at most two communication round trips from proposal broadcast to committed action. Each proposal carries the action primitive identifier, HIG subtask identifier, required resource set, the LIM softmax score, and a monotonically increasing sequence number. Each receiving peer computes:
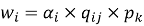
where
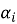
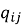
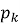
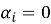
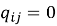
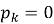
The HIG is a directed acyclic graph replicated across all active nodes under cryptographic verification. Level 1 encodes global mission objectives as formal logical predicates. Level 2 decomposes each objective into operational subtask nodes assignable to individual agents. Level 3 maps subtasks to executable action primitives. Enabling-dependency edges specify completion prerequisites; resource-dependency edges specify mutually exclusive access requirements. Each edge carries a priority weight in. Modifications propagate as signed delta messages; a receiving node applies a delta only after signature verification and confirmation that the update introduces neither a DAG cycle nor a priority-weight violation. Convergence across up to 100 active nodes occurs within 10 ms under nominal network conditions; for up to 1,000 nodes, within 50 ms. Agent failures trigger distributed replanning through the same CWPA pathway as ordinary conflicts, with no separate replanning authority required.
During processor cycles not occupied by active CWPA participation or LIM inference, a conditional variational predictive model takes the 2-second Observation Vector history and the current local HIG state as input and produces a ranked list of anticipated state transitions. Each transition is annotated with an estimated probability
π
and a time-to-occurrence distribution parameterized as a log-normal with mean
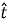
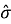
The predictive model is trained offline on domain-representative data. Sensitivity analysis conducted during the simulation study showed that when unrecognized event types exceed approximately 30 % of the event population, TUB hit rate drops below 20 % and median latency reverts to the reactive LIM inference range of 15–35 ms for those categories. An online adaptation mechanism would address this boundary and represents the most consequential direction for future development.
Tier 1 activates when one or more peers become unreachable while the remaining nodes form a connected subgraph. The CWPA continues over the reachable set; weight normalization in Phase 3 is adjusted to sum over responding nodes only, preserving mathematical consistency. Tier 2 activates under full network partition. Each disconnected subgraph operates with its local HIG replica and its own CWPA instance; every intra-subgraph conflict resolves without exception, while inter-subgraph resource arbitration queues until healing. Partition healing triggers a merge protocol that reconciles divergent replicas in causal order, using timestamps and certificate sequence numbers to resolve ambiguous concurrency. Tier 3 activates when a node loses all peer communication. Solo Operation Mode tightens the constraint evaluator to exclude any action requiring a shared resource whose current allocation state cannot be verified locally. TUB retrieval continues at full speed because it operates independently of peer connectivity.
All experiments used a custom discrete-event simulation environment implemented in Python 3.11, with each DAN subcomponent as a standalone module communicating through protocol-compliant message-passing interfaces. To establish simulation validity, the two-node CWPA case was tested against the analytically derived termination bound under deterministic network conditions, confirming exact agreement. HIG synchronization convergence under 100 nodes was compared against the theoretical Gossip protocol round-complexity bound from Karp et al. (2000), converted to milliseconds under the assumption of 0.1 ms per-round link latency consistent with IEEE 802.15.4 measurements; simulated convergence of 9.3 ms (SD = 0.7 ms) confirmed consistency with the theoretical prediction of 10 ms.
Network communication was modeled as a probabilistic delay channel with per-link latency drawn from log-normal distributions fitted to published IEEE 802.11p vehicle-to-vehicle and IEEE 802.15.4 industrial mesh measurements. All reported metrics are means over 30 independent runs, each with a distinct random seed governing topology initialization, traffic demand generation, and node failure timing.
Vehicle fleet experiments used a 16 × 16 synthetic urban grid with randomized traffic demand matrices generating 8–22 conflict pairs per second across fleets of 20, 50, and 100 vehicles. The cloud-centralized reference used an identical routing logic on a single-server scheduler; round-trip latency was set to 85 ms consistent with published cloud coordination measurements (Zhong et al., 2023, pp. 6325–6326), and computational load was modeled as a linear function of active conflict pairs at 0.8 ms per pair. Node failure was induced by disabling 50 % of nodes at simulation minute 5 and restoring them at minute 10; failure-condition metrics average over the 5-minute failure window. Manufacturing experiments used cells of 12, 24, and 48 nodes with fixture pools at 25 % of robotic population (high contention) and 75 % (low contention). Warehouse experiments used a 200 × 60 m facility model with 40 mobile robots, metallic shelving modeled as 35 % packet-loss zones, and mixed aisle-access and dock-scheduling conflicts. Between-condition comparisons used two-sided Welch's t-tests at α = 0.05.
Results
Table 1
Conflict resolution latency across operational conditions
|
Condition |
Engine mean (ms) |
95 % CI |
Engine 95th pct (ms) |
Reference mean (ms) |
95 % CI |
Reference 95th pct (ms) |
|
Nominal (20–100 agents) |
38 |
35–41 |
61 |
190 |
181–199 |
400+ |
|
50 % node failure |
47 |
43–51 |
78 |
310 |
291–329 |
520+ (CI: 489–551) |
|
Full network partition |
39 |
36–42 |
63 |
N/A |
— |
— |
Table 2
Manufacturing cell throughput improvement over centralized scheduling
|
Cell size |
Improvement |
95 % CI |
p-value |
|
12 nodes |
22 % |
18–26 % |
< 0.01 |
|
24 nodes |
27 % |
23–31 % |
< 0.01 |
|
48 nodes |
31 % |
27–35 % |
< 0.01 |
|
Low contention (all sizes) |
~0 % |
— |
0.31 (n.s.) |
Mean conflict resolution latency under nominal conditions was 38 ms (95 % CI: 35–41 ms) across all tested fleet sizes, against 190 ms (95 % CI: 181–199 ms) for the centralized reference. The ratio of approximately 5:1 in mean latency and greater than 6.5:1 at the 95th percentile remained stable from 20 to 100 agents, consistent with the topological prediction that CWPA requires two message hops between affected agents while the reference requires four through a remote controller. Behavior beyond 100 agents requires separate empirical characterization.
Under 50 % node failure, engine mean latency rose to 47 ms (95 % CI: 43–51 ms), a 24 % increase from nominal values. Reference mean latency reached 310 ms (95 % CI: 291–329 ms), with 18 % of resolution attempts failing to complete within the 500 ms timeout; at the 95th percentile, reference latency exceeded 520 ms (CI: 489–551 ms). Node loss reduces the CWPA responding population but creates no additional processing burden on remaining nodes. In the centralized reference, failures increase controller queue contention through compounding feedback absent from the distributed design, which accounts for the asymmetric degradation magnitude.
Under full network partition, the engine maintained 39 ms mean latency (95 % CI: 36–42 ms) within each subgraph, a value statistically indistinguishable from nominal (p = 0.47, Welch's t-test). The reference architecture produced no successful resolutions. The Tier 2 degradation specification therefore corresponds to a measurable operational outcome.
TUB retrieval handled 38 % of conflict events at 20 agents and 52 % at 100 agents, with the increase at higher fleet density reflecting greater recurrence of intersection occupancy and lane-merge conflicts for which the predictive model had been trained. For TUB-handled events, per-decision inference contribution dropped from 15–35 ms to under 2 ms; remaining latency was dominated by CWPA broadcast and voting phases. Above the 30 % out-of-distribution threshold identified in the sensitivity analysis, hit rates dropped sharply, confirming that TUB benefits depend on training data coverage.
Throughput improvements in high-contention cells were 22 %, 27 %, and 31 % for 12-, 24-, and 48-node configurations respectively (all p < 0.01, Welch's t-test; individual CIs in Table 2). The improvement reflects the softmax score
Robots operating within 35 % packet-loss shelving zones continued executing TUB-precomputed pick-and-place policies without coordination loss, consistent with Tier 1 degradation behavior. Robots with active peer links arbitrated aisle access and dock scheduling through CWPA with mean latency of 41 ms (95 % CI: 38–44 ms), 8 % above the open-floor nominal of 38 ms and attributable to increased retransmission under burst packet loss. Robots carrying time-critical orders won dock access arbitration in 94 % of contested cases where the HIG urgency weight differential exceeded 0.3.
Discussion
The factor-of-five mean latency advantage over the centralized reference follows from eliminating the controller from the arbitration communication path. Within the tested range of 20 to 100 agents, the advantage was uniform and showed no trend toward narrowing at higher fleet sizes, consistent with the theoretical prediction that CWPA latency is bounded by neighborhood communication time rather than growing with total fleet population. The 24 % engine latency increase under 50 % node failure contrasts with the 63 % increase for the centralized reference. That difference reflects the absence of a scheduling load-feedback loop in the distributed design, a structural property of the mesh topology rather than a tuning outcome.
Structural exclusion of constraint violations at the policy generation stage shifts safety responsibility from runtime neural behavior to the vocabulary specification process. The residual risk of incomplete specification is qualitatively different from the unbounded distribution-shift risk of purely neural systems: it is bounded, auditable, and addressable through engineering review of the constraint vocabulary. Deployments where that vocabulary can be exhaustively specified benefit most from this property; domains with highly open-ended action spaces gain less because the specification burden becomes significant. Hardware deployments must also account for the 4 TOPS minimum compute requirement per node; below this threshold, the symbolic-only LIM variant preserves CWPA and HIG fault-tolerance properties while sacrificing neural adaptivity.
All results derive from simulation rather than physical deployment. The simulation was validated against analytical bounds and uses network parameters from published hardware measurements, but burst packet-loss patterns in real warehouse environments may not be fully captured by the log-normal delay model. The CWPA has been empirically characterized only up to 100 agents; message volume under very large neighborhood radii at greater scales has not been measured. Above approximately 30 % unrecognized event types, TUB hit rate collapses below 20 % and median latency reverts to the reactive inference range for those categories; an online adaptation mechanism would address this boundary and constitutes the most consequential direction for future work.
Conclusion
Hub-and-spoke coordination topologies impose latency, resilience, and state-consistency costs that are properties of the communication graph itself and cannot be resolved through engineering improvements within that topology. Moving arbitration authority to the agent mesh replaces controller round-trips with two-hop peer exchanges and replaces qualitative resilience claims with operationally specified per-tier performance bounds. Within the tested range of 20 to 100 agents, the architecture achieves a factor-of-five latency reduction, sustains full intra-partition coordination under network disruption, and delivers 22–31 % throughput gains in high-contention manufacturing scenarios. These outcomes are attributable to structural properties of the design rather than to parameter tuning.
The case for this architecture is strongest in deployment domains where the constraint vocabulary can be exhaustively specified in advance and where hardware meeting the 4 TOPS threshold per node is available. Future work should prioritize an online adaptation mechanism for the TUB predictive model, which would extend predictive benefits to environments differing substantially from training conditions and remove the most significant remaining operational boundary identified in this study.
References:
- Cao, Y. U., Fukunaga, A. S., & Kahng, A. (1997). Cooperative mobile robotics: Antecedents and directions. Autonomous Robots, 4 (1), 7–27. https://doi.org/10.1023/A:1008855018923
- Dresner, K., & Stone, P. (2008). A multiagent approach to autonomous intersection management. Journal of Artificial Intelligence Research, 31 , 591–656. https://doi.org/10.1613/jair.2502
- Farinelli, A., Iocchi, L., & Nardi, D. (2004). Multirobot systems: A classification focused on coordination. IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 34 (5), 2015–2028. https://doi.org/10.1109/TSMCB.2004.832155
- Fischer, M. J., Lynch, N. A., & Paterson, M. S. (1985). Impossibility of distributed consensus with one faulty process. Journal of the ACM, 32 (2), 374–382. https://doi.org/10.1145/3149.214121
- Garcez, A. d'Avila, & Lamb, L. C. (2023). Neurosymbolic AI: The 3rd wave. Artificial Intelligence Review, 56 (11), 12387–12406. https://doi.org/10.1007/s10462–023–10448-w
- Gilbert, S., & Lynch, N. (2002). Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services. ACM SIGACT News, 33 (2), 51–59. https://doi.org/10.1145/564585.564601
- Jennings, N. R. (1993). Commitments and conventions: The foundation of coordination in multi-agent systems. The Knowledge Engineering Review, 8 (3), 223–250. https://doi.org/10.1017/S0269888900000205
- Karp, R., Schindelhauer, C., Shenker, S., & Vöcking, B. (2000). Randomized rumor spreading. In Proceedings of the 41st Annual Symposium on Foundations of Computer Science (pp. 565–574). IEEE. https://doi.org/10.1109/SFCS.2000.892324
- Lamport, L., Shostak, R., & Pease, M. (1982). The Byzantine generals problem. ACM Transactions on Programming Languages and Systems, 4 (3), 382–401. https://doi.org/10.1145/357172.357176
- Lynch, N. A. (1996). Distributed algorithms . Morgan Kaufmann. https://doi.org/10.1016/C2009–0-21928–9
- Parker, L. E. (1998). ALLIANCE: An architecture for fault tolerant multirobot cooperation. IEEE Transactions on Robotics and Automation, 14 (2), 220–240. https://doi.org/10.1109/70.681242
- Pierson, A., & Schwager, M. (2018). Adaptive inter-robot trust for robust multi-robot sensor coverage. In Robotics Research (pp. 167–183). Springer. https://doi.org/10.1007/978–3-319–60916–4_10
- Smith, R. G., & Davis, R. (1980). Frameworks for cooperation in distributed problem solving. IEEE Transactions on Systems, Man, and Cybernetics, 11 (1), 61–70. https://doi.org/10.1109/TSMC.1981.4308580
- Stone, P., & Veloso, M. (2000). Multiagent systems: A survey from a machine learning perspective. Autonomous Robots, 8 (3), 345–383. https://doi.org/10.1023/A:1008942012299
- Tanenbaum, A. S., & Van Steen, M. (2007). Distributed systems: Principles and paradigms (2nd ed.). Prentice Hall. ISBN: 978–0-13–239227–3
- Zhong, J., Wang, T., & Luo, Y. (2023). Latency-aware cooperative perception in autonomous vehicle networks. IEEE Transactions on Intelligent Transportation Systems, 24 (6), 6321–6334. https://doi.org/10.1109/TITS.2023.3243543

