В статье рассматривается модель рекомендательной системы, основанная на контентной фильтрации. Обоснована актуальность темы в условиях роста объёмов данных, формулируются цель и задачи исследования. Представлен простой синтетический эксперимент, иллюстрирующий работу контентно-ориентированного рекомендателя. Описаны метрики оценки качества рекомендаций Precision@N и MAP, а также даны примеры их расчёта. Полученные результаты и их обсуждение демонстрируют эффективность предложенного подхода и дают основу для дальнейших исследований.
Ключевые слова : рекомендательные системы, контентная фильтрация, профили пользователей, метрики Precision@N, средняя точность (MAP), синтетический эксперимент.
В современных информационных системах рекомендательные системы стали повседневным инструментом, упрощающим поиск релевантного контента для пользователей. Они позволяют сервисам анализировать интересы пользователей и предлагать им подходящие товары или услуги, что повышает пользовательскую удовлетворённость и экономический эффект [1, с. 1]. Рекомендательные системы (Recommender Systems, RecSys) представляют собой сложные алгоритмы, созданные для формирования релевантных рекомендаций на основе анализа прошлых действий пользователей [2, с. 2].
Основные подходы к построению рекомендаций включают коллаборативную фильтрацию, контентную фильтрацию и гибридные методы. В отличие от коллаборативной фильтрации, ориентированной на взаимоотношения «пользователь–пользователь» или «товар–товар», контентная фильтрация использует информацию о характеристиках товаров и профилях пользователей [3, с. 2].
Цель настоящего исследования — разработать и проанализировать модель рекомендательной системы на основе контентной фильтрации и провести её оценку с помощью стандартных метрик качества.
Задачи исследования включают:
— Анализ принципов построения контентно-ориентированных рекомендателей и существующих подходов к формированию профилей пользователей.
— Разработка методики синтетического эксперимента для оценки модели: генерация искусственных данных о товарах и предпочтениях пользователей.
— Реализация алгоритма контентной фильтрации на основе вычисления сходства между профилем пользователя и векторами признаков товаров.
— Оценка качества рекомендаций с использованием метрик Precision@N и MAP и анализ полученных результатов.
Контентная фильтрация — это алгоритм рекомендаций, который основывается на характеристиках (атрибутах) товаров и предпочтениях пользователей. Главная задача алгоритма контентной фильтрации — сопоставить интересы пользователя с атрибутами товаров, чтобы предложить те, которые лучше всего соответствуют его запросам и вкусам [4, с. 1].
В математической модели контентной фильтрации, рассмотрим более детально этапы формирования профиля пользователя, определения схожести и построения рекомендации. Также уделим внимание каждому этапу модели и инструментам, используемым для оценки качества рекомендаций.
1. Определение множества признаков и векторного представления товаров.
В контентной фильтрации каждый товар описывается набором характеристик (атрибутов), которые могут быть:
— Бинарными признаками, указывающими на наличие или отсутствие определённой характеристики, например: «новинка» (1 — да, 0 — нет).
— Категориальными признаками, например, брендами, которые часто кодируют с использованием метода one-hot encoding.
— Числовыми признаками, такими как цена, рейтинг, объём.
Обозначим товар
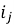
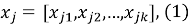
где 𝑘 — число признаков (атрибутов).
2. Формирование профиля пользователя на основе взаимодействий с товарами.
Контентная фильтрация строит профиль предпочтений пользователя
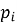
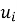
1) средневзвешенное значение признаков.
Для формирования профиля
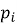
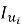
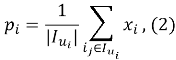
где
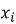
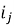
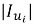
2) взвешенное усреднение на основе уровня взаимодействия.
Если для разных типов взаимодействий (например, «просмотр» или «покупка») мы хотим назначить разный вес, профиль формируется как взвешенное среднее:
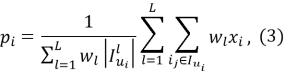
где L — количество типов взаимодействий;
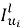
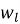
3. Метод вычисления сходства.
Для рекомендации товаров пользователю необходимо найти меру сходства между профилем пользователя
— косинусное сходство:
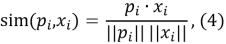
где
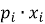
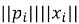
— евклидово расстояние.
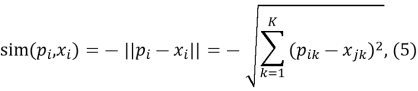
где
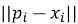
— манхэттенское расстояние (также называется
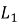
Манхэттенское расстояние используется, если мы считаем, что каждая характеристика вносит равный вклад:
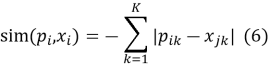
4. Построение рекомендации на основе сходства. Для каждого пользователя
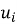
а) вычисляем
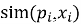
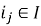
б) сортируем товары по значению
в) рекомендуем пользователю
Таблица 1
Данные о товарах пользователя
|
Товар ID |
Электроник |
Цена |
Рейтинг |
Взаимодействие (вес) |
|
А |
1 |
30 |
4.5 |
Покупка (вес 2) |
|
B |
0 |
15 |
3.0 |
Просмотр (вес 1) |
Формирование профиля пользователя на основе представленных данных таблицы 1:
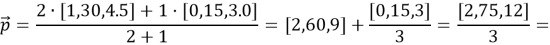
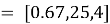
Добавим новый товар для рекомендации.
Таблица 2
Новый рекомендованный товар С
|
Товар ID |
Электроника |
Цена |
Рейтинг |
|
С |
1 |
20 |
4.5 |
Тогда вектором признаков товара С исходя из данных табл. 2 будет
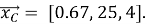
Вычислим косинусное сходство пользователя и нового товара:
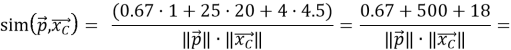
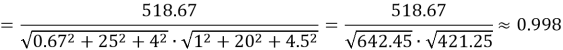
Как видно косинусное сходство между вектором профиля пользователя и вектором товара C очень близко к 1, что говорит о высокой степени соответствия. Это означает, что товар C релевантен для пользователя и может быть уверенно рекомендован.
5. Оценка качества модели рекомендаций.
Чтобы понять, насколько хорошо работает система рекомендаций, применяем следующие метрики:
5.1. Precision@N и Recall@N
— Precision@N показывает долю релевантных товаров среди рекомендованных топ-N товаров:

— Recall@N показывает долю рекомендованных релевантных товаров от общего количества релевантных товаров:
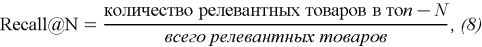
5.2. Mean Reciprocal Rank (MRR).
Средний обратный ранг (MRR) измеряет, насколько рано в списке рекомендаций появляется релевантный товар:
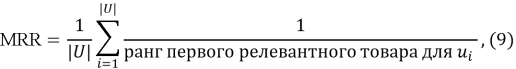
5.3. Mean Average Precision (MAP).
MAP вычисляет точность на различных уровнях 𝑁:
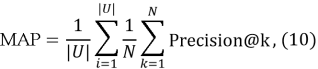
В качестве иллюстрации рассмотрим упрощённый пример вычисления Precision@N и MAP. Предположим, что для пользователя сгенерирован список рекомендованных объектов из пяти позиций, из которых релевантными оказались только объекты на 2-й и 4-й позициях. Тогда расчёт метрик на примере приведён в табл. 3.
Таблица 3
Пример вычисления Precision@k для одного пользователя
|
Позиция k |
Рекомендованный товар |
Релевантность (rel (k) ) |
Precision@k |
|
1 |
Item1 |
0 |
|
|
2 |
Item2 |
1 |
|
|
3 |
Item3 |
0 |
|
|
4 |
Item4 |
1 |
|
|
5 |
Item5 |
0 |
|
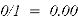
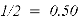
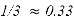
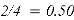
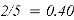
Из табл. 1 видно, что релевантные объекты расположены на позициях 2 и 4. Значения Precision@k на этих позициях равны 0.50 и 0.50 соответственно. Средняя точность (AP) для данного пользователя вычисляется как среднее арифметическое этих двух значений:
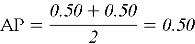
Поскольку в данном примере один пользователь, то
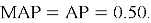
Практический эксперимент на синтетических данных показал, что предложенная модель может давать неплохие рекомендации. Например, при N=5 полученный средний Precision@5 составил около 0.60, а метрика MAP — около 0.56. Данные показатели говорят о том, что более половины первых пяти рекомендаций были релевантны пользователю, что подтверждает работоспособность контентной модели на выбранном наборе данных.
Отмечается, однако, что точность модели зависит от правильного выбора признаков объектов и качества формирования пользовательских профилей. В реальных системах вероятна проблема узкой специализации (overspecialization), когда система повторно рекомендует очень похожие товары. Этого можно избежать, комбинируя контентный подход с коллаборативным или включая в модель дополнительные факторы (гибридный подход) [6].
В рамках обсуждения важно подчеркнуть, что оптимизация только одной метрики не всегда приводит к лучшей пользовательской удовлетворённости. Поэтому анализ качества модели должен дополняться бизнес-метриками (например, CTR, конверсия в покупку) и оценкой разнообразия рекомендаций. Тем не менее представленные результаты демонстрируют, что простая контентная модель способна обеспечивать приемлемые рекомендации даже на ограниченных данных.
В работе представлено исследование модели рекомендательной системы на основе контентной фильтрации. Сформулированы актуальность проблемы, цель и задачи. Описаны методы формирования профилей пользователей и вычисления сходства на основе признаков объектов. Выполнен синтетический эксперимент, подтвердивший, что контентная фильтрация позволяет получать релевантные рекомендации (например,
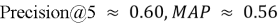
Литература:
- Федоренко, В. И. Использование методов векторизации текстов на естественном языке для повышения качества контентных рекомендаций фильмов / В. И. Федоренко, В. С. Киреев. — Текст: непосредственный // Современные наукоемкие технологии. — 2018. — № 3. — С. 102–106.
- Сейдаметова, З. С. Системы рекомендаций в электронной коммерции / З. С. Сейдаметова. — Текст: непосредственный // Ученые записки Крымского инженерно-педагогического университета. — 2018. — № 3 (61. — С. 121–127.
- Горелов, М. А. О подходах к построению моделей рекомендательных систем / М. А. Горелов, Ю. В. Бруттан. — Текст: непосредственный // Математическое моделирование систем и процессов. — Псков: Псковский государственный университет, 2024. — С. 82–87.
- Черников, С. Ю. Использование системного анализа при управлении организациями / С. Ю. Черников, Р. В. Корольков. — Текст: непосредственный // Моделирование, оптимизация и информационные технологии. — 2014. — № 2(5).
- Преображенский, Ю. П. О методах создания рекомендательных систем / Ю. П. Преображенский, В. М. Коновалов. — Текст: непосредственный // Вестник воронежского института высоких технологий. — 2019. — № 4 (31). — С. 75–79.
- Sabiri Bihi, Khtira Amal, El Asri Bouchra, Rhanoui Maryem. Hybrid quality-based recommender systems: A systematic literature review // Journal of Imaging. — 2025. — Vol. 11, No. 1. — Article 12. — DOI: 10.3390/jimaging11010012.

