В статье проводиться анализ методов создания синтетических обучающих выборок с помощью готовых библиотек языка программирования Python и разработанных генеративных моделей. Помимо этого исследование направлено на изучение различных способов организации данных для обучения моделей на примере FaceNet.
Ключевые слова: машинное и глубокое обучение, генеративно-состязательные сети, GAN, Self-Attention GAN, вариационные автоэнкодеры, VAE, FFHQ, синтетические обучающие выборки, синтетические данные, реальные данные.
В настоящее время для обучения моделей машинного обучения, состоящих из множества настраиваемых параметров, требуется большое число размеченных и неразмеченных данных. Однако добыча таких данных может потребовать значительного количества временных, вычислительных и технических ресурсов. К тому же получение некоторых данных может быть затруднительным из-за конфиденциальности и защиты персональных данных. Поэтому для решения указанных проблем были разработаны методы генерации синтетических данных.
Синтетические данные — искусственные наборы данных, имитирующие свойства реальных объектов. Синтетические данные можно условно разбить на две группы: структурированные (таблицы, базы данных) и неструктурированные (текст, числа, видеофрагменты, аудио, изображения). Для получения таких данных разработано множество методов генерации: генеративные модели, математические модели и методы рандомизации (генераторы псевдослучайных чисел).
Для языка программирования Python есть специальные библиотеки, позволяющие создавать синтетические данные. К ним можно отнести Faker, Scikit-learn, Synthetic Data Vault и другие. Например, Faker предоставляет возможность создавать данные, которые содержат персональную информацию, такую как: дата рождения, ФИО, электронный адрес, адрес места жительства, сотовый номер и т. п. Перед их генерацией нужно указать локального поставщика для конкретного языка и региона. Пример использования библиотеки представлен на рис. 1.
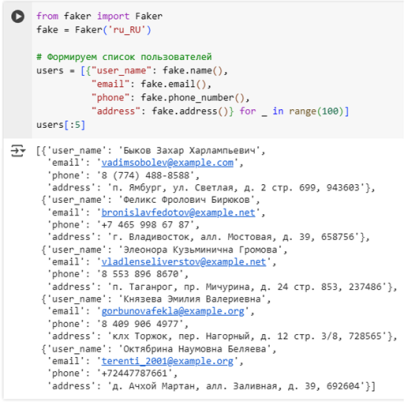
Рис. 1. Генерация персональных данных
Другой немаловажной библиотекой является Scikit-learn, которая предлагает функции по формированию синтетических обучающих выборок с целью решения задач классификации (make_classification), регрессии (make_regression) и кластеризации (make_blobs). На рис. 2 проиллюстрирован процесс обучения и построения линейной регрессии.
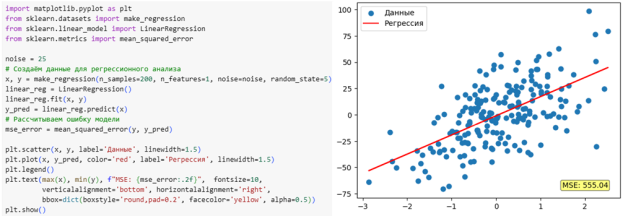
Рис. 2. Генерация данных для линейной регрессии
Библиотека Synthetic Data Vault учитывает статистические свойства реальных данных с помощью статистических моделей (например, Гауссова копула). На рис. 3 показан пример подготовки синтетической обучающей выборки.
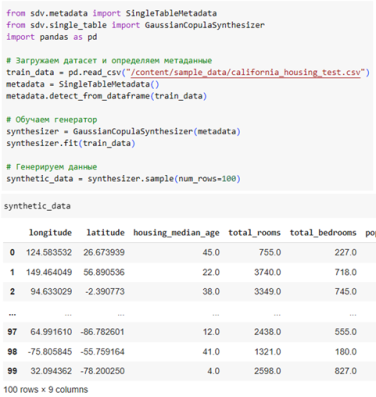
Рис. 3. Подготовка выборки
Перейдём к рассмотрению генеративных моделей, которые помимо других типов данных позволяют создавать синтетические изображения.
Для обучения генеративных моделей использовался набор данных о лицах, который содержит 70 тысяч лиц
За последнее десятилетие было предложено множество генеративных моделей: генеративно-состязательные сети, вариационные автоэнкодеры, диффузионные модели.
Вариационные автоэнкодеры представляют собой класс моделей неконтролируемого обучения, в состав которых входят два основных компонента: кодировщик и декодировщик. Кодировщик преобразует многомерное пространство в дисперсию и стандартное среднее нормального распределения [5, с. 2]. Затем эти параметры используются для сэмплирования в вектор скрытого пространства. Декодировщик выполняет обратную автокодировщику операцию. Он пытается наиболее точно восстановить многомерное пространство из вектора скрытого пространства. Таким образом, основная цель VAE — нахождение оптимального распределения для получения вектора скрытого пространства, с помощью которого можно наиболее точно восстановить синтетическое изображение. Для обучения модели необходимо оптимизировать общую функцию потерь, которая состоит из потерь реконструкции и дивергенции Кульбака-Лейблера.
Основным недостатком таких сетей является создание размытых изображений, которые представлены на рис. 4.

Рис. 4. Сгенерированные образцы моделью VAE
Генеративно-состязательные сети составляют класс моделей, обучение которых заключается в состязательной игре двух игроков [1, с. 213]. Первый игрок старается обмануть второго игрока, создавая поддельные данные, а второй игрок определяет, какие данные к нему поступили. Итогом данной игры является нахождение равновесия Нэша.
В качестве первого игрока в этой игре выступает генератор
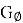
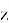
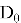
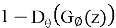
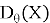
В ходе обучения, генератор и дискриминатор подстраивают свои параметры. Наилучшее состояние достигается, когда оптимальный дискриминатор не может определить, какие данные к нему поступили. В этом случае распределение реальных и сгенерированных данных эквивалентно.
В нашей работе для создания синтетических изображений используется генеративно-состязательная сеть с механизмом самовнимания — Self-Attention GAN [6]. На вход в блок внимания поступает карта признаков, она преобразуется в три пространства признаков f, g, h, из них для f и g выполняется матричное произведение, затем рассчитывается выходная карта внимания. Теперь выполняется матричное произведение для выходной карты внимания и пространства признаков h. При этом
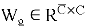
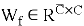
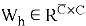
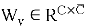
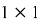
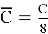
В результате обучения состязательной сети, на 170 эпохе были получены сгенерированные образцы, представленные на рис. 5.
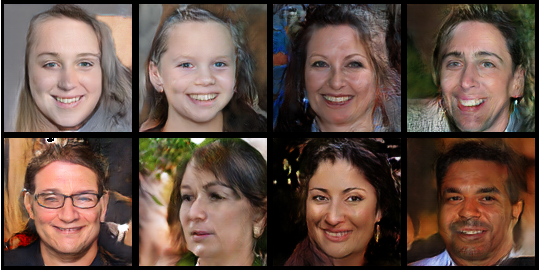
Рис. 5. Сгенерированные образцы моделью SAGAN
Дальше мы обучили модель FaceNet [4] на датасете, содержащем смешанный набор данных (реальные и сгенерированные), размер реальной выборки составил 17334 лица, а сгенерированные образцы использовались для расширения датасета и составили 15 % от размера реальной выборки. При этом точность на тренировочной выборке равна примерно 0.88671, ошибка — 0.04740. График изменения точности можно наглядно увидеть на рис. 6.
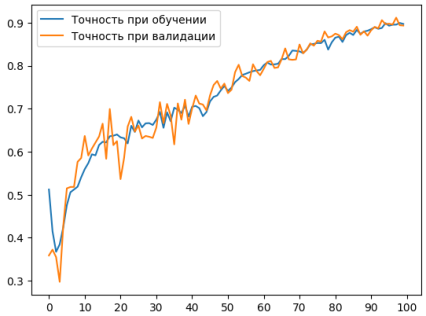
Рис. 6. График изменения точности
Обученную модель мы использовали для решения таких задач машинного обучения, как: кластеризация, идентификация и верификация.
В таблице 1 представлены результаты расчётов показателей метрик для обученных моделей FaceNet с помощью разных способов организации обучающей выборки.
Таблица 1
Оценка моделей, обученных на разных способах разбиения данных
|
Способ разбиения\Метрика |
Precision |
Recall |
F1-мера |
Accuracy |
Specifity |
Loss |
|
с синтетическими данными |
≈0.8684 |
≈0.8684 |
≈0.8684 |
≈0.8684 |
≈0.8684 |
≈0.0765 |
|
только с реальными данными |
≈0.6298 |
≈0.6298 |
≈0.6298 |
≈0.6298 |
≈0.6298 |
≈0.1773 |
|
с аугментированными данными |
≈0.5469 |
≈0.5469 |
≈0.5469 |
≈0.5469 |
≈0.5469 |
≈0.1209 |
Исходя из показателей, можно сделать вывод, что лучшей моделью оказалась та, которая обучалась на смешанных данных (реальные и синтетические).
Литература:
- Durall, R. Combating Mode Collapse in GAN training: An Empirical Analysis using Hessian Eigenvalues / R. Durall. — Текст: электронный // arXiv: [сайт]. — URL: https://arxiv.org/pdf/2012.09673 (дата обращения: 27.05.2025).
- Goodfellow, I. Generative Adversarial Networks / I. Goodfellow. — Текст: электронный // arXiv: [сайт]. — URL: https://arxiv.org/pdf/1406.2661 (дата обращения: 27.05.2025).
- Heusel, M. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium / M. Heusel. — Текст: электронный // arXiv: [сайт]. — URL: https://arxiv.org/pdf/1706.08500 (дата обращения: 27.05.2025).
- Schroff, F. FaceNet: A Unified Embedding for Face Recognition and Clustering / F. Schroff. — Текст: электронный // arXiv: [сайт]. — URL: https://arxiv.org/pdf/1503.03832 (дата обращения: 27.05.2025).
- Vivekananthan, S. Comparative analysis of generative models: enhancing image synthesis with vaes, gans, and stable diffusion / S. Vivekananthan. — Текст: электронный // arXiv: [сайт]. — URL: https://arxiv.org/pdf/2408.08751 (дата обращения: 27.05.2025).
- Zhang, H. Self-Attention Generative Adversarial Networks / H. Zhang. — Текст: электронный // arXiv: [сайт]. — URL: https://arxiv.org/pdf/1805.08318 (дата обращения: 27.05.2025).

