В статье представлен метод типизации документов для интеллектуальной обработки документов (IDP), основанный на триплетном обучении с использованием функции потерь TripletMarginLoss. Предлагаемый подход объединяет визуальные и текстовые признаки документов, формируя устойчивые эмбеддинги, которые эффективно кластеризуют документы по типам в многомерном пространстве. Использование триплетного лосса позволяет повысить точность типизации даже при наличии множества визуально схожих, но семантически различных шаблонов. Для классификации новых документов применяется метод ближайших соседей с параметром k=1. Полученные результаты подтверждают эффективность подхода и его пригодность для настройки управления в IDP-приложениях.
Ключевые слова: интеллектуальная обработка документов, IDP, типизация документов, триплетное обучение, TripletMarginLoss, эмбеддинги, ResNet, RuBERT, метрическое обучение, классификация документов, метод ближайших соседей.
Интеллектуальная обработка документов (IDP, Intelligent Document Processing ) — это совокупность технологий, позволяющих автоматизировать извлечение, структурирование и проверку данных из неструктурированных источников, таких как сканы, PDF-документы и изображения.
Ключевым этапом в работе любой IDP-системы является типизация документов — определение их класса или назначения (например, счёт, акт, договор, накладная). Тип документа определяет, какие поля нужно извлекать, какие правила проверки и маршрутизации применимы, каким пользователям или подсистемам передавать данные. Без надёжной типизации невозможно построить эффективные маршруты обработки, автоматические проверки и визуальные интерфейсы для управления системой.
В данной статье рассматривается подход к типизации документов с использованием триплетного обучения и функции потерь TripletMarginLoss, позволяющий формировать устойчивые эмбеддинги [1] документов и различать их по смысловым признакам [2]. Этот метод позволяет повысить точность типизации даже при наличии множества визуально схожих [3], но семантически различных шаблонов, и служит надёжной основой для последующей настройки управления в IDP-приложении. [4]
Пайплайн типизации состоит из трёх основных этапов: извлечение визуальных и текстовых признаков, объединение эмбеддингов и обучение с помощью триплетной функции потерь.
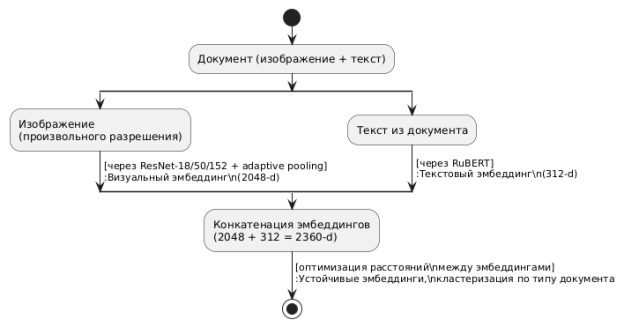
Рис. 1. Пайплайн типизации документов
На вход подаётся изображение документа произвольного разрешения [5]. Визуальные признаки извлекаются с помощью сверточной сети ResNet (в зависимости от задачи применяются ResNet-18, 50 или 152). После последнего сверточного слоя применяется адаптивный пулинг (adaptive pooling), в результате чего формируется вектор признаков размерности 2048.
Параллельно из документа извлекается текст, который преобразуется в эмбеддинг с использованием модели RuBERT [6]. Размерность текстового эмбеддинга составляет 312.
Визуальный и текстовый эмбеддинги конкатенируются в единый вектор длиной 2352 и передаются на вход полносвязной нейронной сети с 2–3 слоями и активацией ReLU. Обучение модели осуществляется с использованием функции потерь TripletMarginLoss, которая минимизирует расстояние между эмбеддингами документов одного типа и максимизирует расстояния между эмбеддингами документов разных типов [7].
Этот метод устойчив [8] к вариативности шаблонов и обеспечивает семантическую кластеризацию документов по типу, что критично для управления IDP-системой.
Принцип работы Triplet Loss
Обучение модели типизации осуществляется с использованием функции потерь TripletMarginLoss, основанной на триплетном обучении. [2] В отличие от классических методов классификации, триплетный подход направлен не на предсказание метки, а на формирование метрического пространства, в котором документы одного типа расположены ближе друг к другу, чем к документам других типов. [9]
Каждое обучающее обновление модели осуществляется на основе триплета — упорядоченной тройки входных данных:
— Anchor ( якорь ) — исходный документ;
— Positive — документ того же типа, что и якорь;
— Negative — документ иного типа.
Все три примера последовательно пропускаются через модель, в результате чего формируются три эмбеддинга:
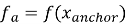
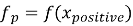
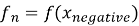
Функция потерь имеет следующий вид:
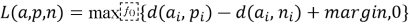
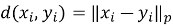
где margin — гиперпараметр, задающий минимально допустимую разницу между расстоянием до негативного и позитивного примеров. В ходе обучения оптимизируется условие, при котором расстояние между эмбеддингами якоря и негативного примера превосходит расстояние до позитивного хотя бы на величину margin. [10]
Цель обучения — минимизировать эту функцию, обеспечивая выполнение неравенства:
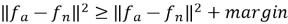
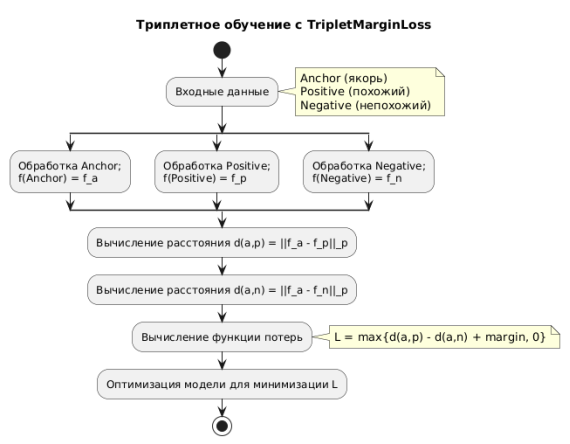
Рис. 2. Триплетное обучение с TripletMarginLoss
Таким образом, функция потерь направлена на сближение документов одного класса и разведение документов разных классов в эмбеддинговом пространстве. В результате формируется кластерная структура: каждый тип документа представлен отдельной компактной областью, что позволяет надёжно определять тип новых, ранее не встречавшихся документов по их положению в этом пространстве.
Классификация новых документов
После завершения обучения модель может быть использована для типизации новых документов. Процедура классификации базируется на сравнении эмбеддингов в построенном метрическом пространстве.
Для каждого нового документа извлекается векторное представление (эмбеддинг) с помощью обученной модели. Далее производится поиск ближайшего соседа среди эмбеддингов обучающей выборки в соответствии с выбранной метрикой (обычно — евклидово расстояние).
В текущей реализации используется метод k ближайших соседей с параметром k = 1 (1-NN). Тип нового документа присваивается на основе класса (типа) наиболее близкого эмбеддинга из обученного множества:
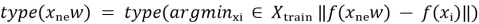
Такой подход прост в реализации и логически продолжает стратегию метрического обучения: тип определяется не по фиксированному классификатору, а по положению в пространстве, организованном во время обучения.
Результаты и их обсуждение
В ходе экспериментов был протестирован описанный метод типизации на выборке документов различных типов, включающей как визуально отличающиеся, так и схожие по структуре шаблоны. Обученная модель, объединяющая визуальные эмбеддинги, полученные с помощью ResNet, и текстовые эмбеддинги из RuBERT, показала высокую стабильность и точность при распознавании типов документов.
Применение функции потерь TripletMarginLoss способствовало формированию хорошо разделимых кластеров в эмбеддинговом пространстве, что подтверждается уменьшением внутрикластерных расстояний и увеличением межкластерных интервалов. Благодаря этому, классификация с помощью метода ближайших соседей (k=1) достигла высокой точности даже на документах, визуально схожих, но различающихся по содержанию.
Данный подход позволяет гибко настраивать логику обработки документов в IDP-системах, так как точное определение типа документа является основой для выбора правил извлечения, проверки и маршрутизации данных. Кроме того, архитектура решения адаптивна к расширению типов документов за счет возможности дообучения модели на новых данных.
В дальнейшем планируется углубленное исследование влияния параметров модели и гиперпараметров TripletMarginLoss на качество кластеризации, а также интеграция с визуальными интерфейсами для удобства администрирования IDP-системы.
Литература:
- Schroff, F., Kalenichenko, D., & Philbin, J. (2015). FaceNet: A Unified Embedding for Face Recognition and Clustering. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 815–823.
- Hermans, A., Beyer, L., & Leibe, B. (2017). In Defense of the Triplet Loss for Person Re-Identification. arXiv preprint arXiv:1703.07737.
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778.
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of NAACL-HLT, 4171–4186.
- Lowe, D. G. (2004). Distinctive Image Features from Scale-Invariant Keypoints. International Journal of Computer Vision, 60(2), 91–110.
- Gupta, S., & Kaushik, R. (2021). Intelligent Document Processing: A Review. International Journal of Computer Applications, 174(19), 1–8.
- Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems (NeurIPS), 5998–6008.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- Wang, J., Zhou, F., Wen, S., Liu, X., & Lin, Y. (2019). Multi-Similarity Loss with General Pair Weighting for Deep Metric Learning. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5022–5030.
- Balntas, V., Riba, E., Ponsa, D., & Mikolajczyk, K. (2016). Learning Local Feature Descriptors with Triplets and Shallow Convolutional Neural Networks. BMVC 2016.

