В данной статье рассматриваются технологии параллельного программирования, направленные на ускорение выполнения сложных вычислительных алгоритмов. Высокая вычислительная сложность и значительные объемы обрабатываемых данных требуют использования эффективных методов параллелизации, что делает актуальным применение многопоточных и распределённых вычислений. В работе проводится анализ подходов к организации параллельного выполнения задач, исследуется архитектура многопроцессорных систем и рассматриваются ключевые концепции параллельных вычислений. Особое внимание уделяется различным уровням параллелизма, включая параллелизм на уровне алгоритмов, данных, инструкций и потоков. Описаны механизмы многопоточности, её преимущества и роль в оптимизации вычислительных процессов. Рассматривается жизненный цикл потока, включая его основные состояния и методы управления. Анализируются различия между процессно- и поточно-ориентированной многозадачностью, а также их влияние на производительность вычислительных систем. В статье приводятся примеры практического применения параллельного программирования, включая моделирование физических процессов, обработку больших данных, машинное обучение, финансовый анализ, биоинформатику, компьютерную графику и кибербезопасность. Делается вывод о высокой эффективности многопоточного программирования и параллелизма на уровне алгоритмов для решения вычислительно сложных задач. Результаты исследования показывают, что комбинированное использование многопоточности и алгоритмического параллелизма позволяет значительно повысить производительность программных систем, более эффективно использовать доступные аппаратные ресурсы и сократить время выполнения вычислений.
Ключевые слова: параллельное программирование, многопоточность, параллельные алгоритмы, распределённые вычисления, многозадачность, оптимизация вычислений, высокопроизводительные вычисления.
This article explores parallel programming technologies aimed at accelerating the execution of complex computational algorithms. High computational complexity and large volumes of processed data necessitate the use of efficient parallelization methods, making multithreaded and distributed computing highly relevant. The study analyzes approaches to organizing parallel task execution, examines the architecture of multiprocessor systems, and discusses key concepts of parallel computing. Special attention is given to various levels of parallelism, including algorithm-level, data-level, instruction-level, and thread-level parallelism. The mechanisms of multithreading, its advantages, and its role in optimizing computational processes are described. The lifecycle of a thread is examined, including its main states and management methods. Differences between process-oriented and thread-oriented multitasking are analyzed, along with their impact on computing system performance. The article provides practical examples of parallel programming applications, such as physical process modeling, big data processing, machine learning, financial analysis, bioinformatics, computer graphics, and cybersecurity. The study concludes that multithreading and algorithm-level parallelism are highly effective for solving computationally intensive tasks. The research findings indicate that the combined use of multithreading and algorithmic parallelism significantly enhances software system performance, optimizes hardware resource utilization, and reduces computation time.
Keywords: parallel programming, multithreading, parallel algorithms, distributed computing, multitasking, computation optimization, high-performance computing.
Введение
Одной из ключевых проблем при выполнения сложных вычислительных алгоритмов является высокая вычислительная сложность и значительная размерность рассматриваемых задач. Эти факторы обусловлены необходимостью обработки большого количества данных объектов. В связи с этим актуальной задачей становится разработка и применение распределённых мини-моделей и параллельных алгоритмов.
В данной статье рассматриваются методы ускорения выполнения вычислительных алгоритмов, анализируются подходы к параллельному моделированию процессов, а также исследуются возможности использования распределённых алгоритмов и моделей для повышения точности и скорости обработки данных.
Современная разработка программного обеспечения требует глубоких знаний в области параллельного и распределённого программирования. Программные решения должны быть адаптированы к многопроцессорным системам, чтобы эффективно использовать их вычислительные ресурсы. Параллельное выполнение задач означает, что несколько процессов могут выполняться в течение одного и того же временного интервала, однако это не всегда предполагает их строго синхронное исполнение.
Основная цель технологий параллелизма заключается в создании условий, позволяющих компьютерным программам выполнять больший объём вычислений за тот же промежуток времени. Применение параллельных вычислений может быть направлено как на увеличение быстродействия программ, так и на повышение их общей продуктивности без значительного изменения времени выполнения.
Параллельные вычисления
В сфере информационных технологий термин «параллельный» тесно связан с решением вычислительно сложных задач. Важно учитывать, что в данном контексте он заменяет такие понятия, как «одновременный» и «независимый», означая, что отдельные части сложной задачи выполняются автономно, без строгой синхронизации друг с другом.
Параллельные вычисления охватывают широкий спектр аспектов, связанных с созданием и эффективным использованием ресурсов параллелизма в процессе решения задач. Главной целью параллельных технологий является повышение вычислительной эффективности компьютерных систем на различных уровнях. В ряде случаев целесообразно, а иногда и необходимо, организовывать параллельное выполнение отдельных частей программы, что позволяет пользователю воспринимать их как происходящие одновременно.
Каждая из таких независимых подзадач представляет собой поток (thread). При проектировании многопоточных приложений предполагается, что каждый поток запускается автономно и использует процессорные ресурсы в монопольном режиме, обеспечивая тем самым более эффективное распределение вычислительной нагрузки.
Параллелизм на уровне алгоритмов
Данный тип параллелизма основан на замене последовательных алгоритмов вычислений их параллельными аналогами. Это особенно актуально для таких задач, как поиск, сортировка и обработка данных. Организация распараллеливания осуществляется с применением специализированных средств параллельного программирования, включая библиотеки, переменные окружения, директивы компилятора и другие механизмы, обеспечивающие эффективное выполнение вычислительных процессов.
Все операции, связанные с решением задачи, выполняются на битовом уровне, а переход между битовым и более высокими уровнями представления данных осуществляется с использованием аппаратных и программных средств. Эффективность этих переходов напрямую влияет на производительность вычислений. Таким образом, глубокое понимание архитектуры вычислительных систем и механизмов обработки данных на машинном уровне становится особенно важным, если оптимизация на более высоких уровнях, таких как уровень инструкций, данных или задач, оказывается затруднительной или невозможной.
Бит представляет собой минимальную единицу хранения информации. Упорядоченный набор битов формирует машинное слово, которое является базовым информационным элементом компьютера. Длина машинного слова определяется количеством байтов, на которые оно разбивается (обычно 8 бит составляют 1 байт). Параллелизм на уровне битов предполагает изменение размера машинного слова с целью повышения эффективности обработки данных.
Поток (thread) — это структурная единица внутри процесса, содержащая исполнительный код и получающая процессорное время для выполнения своих задач.
Потоки, принадлежащие одному процессу, совместно используют область памяти, исполняемый код и все доступные ресурсы процесса. Аналогично процессам, каждый поток обладает собственным блоком управления, который реализуется в виде набора структур, главной из которых является ETHREAD (Executive Thread Block).
Жизненный цикл потока
В ходе выполнения поток может многократно изменять своё состояние под воздействием различных методов управления. Изначально, до вызова метода Start() , поток находится в состоянии Unstarted . После его запуска статус изменяется на Running , что означает активное выполнение кода.
При вызове метода Sleep() поток переходит в состояние WaitSleepJoin , временно приостанавливая своё выполнение. Если же применяется метод Abort() , поток сначала получает статус AbortRequested , а затем Aborted , после чего его выполнение окончательно прекращается.
Управление состояниями потока является важным аспектом многопоточного программирования, поскольку корректная работа с жизненным циклом потоков позволяет оптимизировать распределение вычислительных ресурсов и избежать нежелательных состояний гонок данных или блокировок.
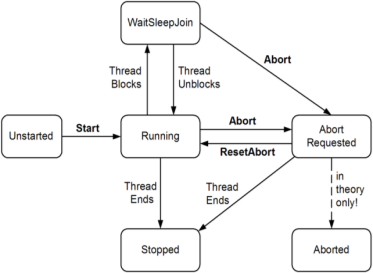
Рис. 1 Жизненный цикл потока
Многопоточность представляет собой свойство платформы (например, операционной системы, виртуальной машины и т. д.) или программного приложения, позволяющее процессу, запущенному в операционной системе, состоять из нескольких потоков, выполняющихся «параллельно» , то есть без строгого порядка во времени. Такое разделение задач способствует более эффективному использованию вычислительных ресурсов системы. Потоки, участвующие в данном процессе, также называют потоками выполнения.
Основы многопоточности
В области многозадачности различают два подхода: процессно-ориентированная многозадачность и поточно-ориентированная многозадачность . Понимание их различий играет ключевую роль в проектировании высокоэффективных вычислительных систем.
Процесс представляет собой исполняемую программу, а процессно-ориентированная многозадачность означает возможность одновременного выполнения нескольких программ на одном вычислительном устройстве. В этом случае программа является минимальной единицей кода, с которой работает планировщик задач.
Поток, в свою очередь, представляет собой управляемую единицу исполняемого кода внутри процесса. В среде, ориентированной на потоки, каждый процесс содержит как минимум один поток, но их может быть и больше. Это позволяет одной программе выполнять несколько задач одновременно, что значительно повышает её эффективность.
Таким образом, ключевое различие между двумя подходами заключается в следующем:
— Процессно-ориентированная многозадачность обеспечивает одновременное выполнение нескольких независимых программ.
— Поточно-ориентированная многозадачность позволяет выполнять несколько частей одной и той же программы параллельно.
Преимущества многопоточности
Основным преимуществом многопоточности является возможность создания высокоэффективных программ за счёт рационального использования периодов вынужденного ожидания (простоя), которые неизбежно возникают во многих вычислительных процессах.
Как известно, скорость работы большинства устройств ввода-вывода (сетевых интерфейсов, дисковых накопителей, клавиатуры и др.) значительно уступает скорости центрального процессора (CPU). В результате значительная часть времени выполнения программы может тратиться на ожидание завершения операций ввода-вывода.
Использование многопоточности позволяет организовать выполнение программ таким образом, чтобы во время таких простоев выполнялись другие задачи, тем самым повышая общую производительность системы.
Практическое применение
Параллельное программирование играет ключевую роль в современных вычислительных системах, обеспечивая значительное ускорение обработки данных и повышение эффективности вычислений. Его применение охватывает широкий спектр областей, включая научные исследования, промышленность и информационные технологии.
Одним из наиболее ярких примеров использования параллельных алгоритмов является моделирование физических процессов. В таких областях, как вычислительная механика, аэродинамика, квантовая химия и молекулярная динамика, требуется обработка огромных объемов данных. Применение многопоточного и распределённого программирования позволяет значительно сократить время расчётов и повысить точность моделирования.
Другой важной сферой является обработка больших данных (Big Data). В эпоху цифровой информации компании и исследовательские организации сталкиваются с необходимостью анализа огромных массивов данных в реальном времени. Параллельные вычисления используются в таких технологиях, как Hadoop, Apache Spark и Google MapReduce, позволяя распределять обработку данных между множеством узлов в кластере.
В последние годы параллельные технологии активно применяются в машинном обучении и искусственном интеллекте. Современные алгоритмы глубокого обучения (Deep Learning) требуют значительных вычислительных мощностей, что делает многопоточность и использование графических процессоров (GPU) важнейшими инструментами для их эффективной работы. Библиотеки, такие как TensorFlow и PyTorch, используют параллельные вычисления для ускорения тренировки нейронных сетей.
Возможные области применения многопоточности и параллельных алгоритмов в индустрии
Параллельное программирование широко применяется в различных отраслях:
- Финансовый сектор — параллельные вычисления используются для высокочастотного трейдинга, моделирования финансовых рисков, прогнозирования и анализа данных.
- Биоинформатика — анализ ДНК, моделирование биологических процессов и обработка медицинских изображений требуют больших вычислительных ресурсов, что делает многопоточность и распределенные вычисления незаменимыми.
- Компьютерная графика и игровые движки — рендеринг изображений, обработка физики объектов в реальном времени и симуляция виртуальных миров активно используют многопоточные вычисления.
- Автономные системы и робототехника — обработка сенсорных данных, навигация и принятие решений в автономных транспортных средствах невозможны без использования параллельных алгоритмов.
- Кибербезопасность — анализ сетевого трафика, обнаружение аномалий и атаки требуют обработки больших объёмов информации с высокой скоростью, что достигается за счёт параллельной обработки данных.
Таким образом, технологии параллельного программирования находят широкое применение во многих областях, способствуя росту производительности вычислительных систем и открывая новые возможности для решения сложных задач, требующих много времени для выполнения вычислений и получения результатов.
Заключение
Одной из ключевых целей данного исследования являлось определение оптимальной архитектуры аппаратной системы и технологии параллельной обработки, наиболее соответствующих вычислительным требованиям выполнения сложных алгоритмов.
На основании проведённого анализа установлено, что крупнозернистый параллелизм на уровне алгоритмов в сочетании с многопоточностью обладают наибольшим потенциалом для ускорения вычислений при решении сложных задач. Это обусловлено преимуществами многопоточной обработки, позволяющей снизить вычислительную сложность и, как следствие, сократить время выполнения алгоритмов.
Кроме того, важным выводом исследования является то, что параллелизм на уровне алгоритмов в сочетании с многопоточностью позволяет более эффективно использовать доступные аппаратные ресурсы компьютера, что дополнительно способствует увеличению производительности и сокращению временных затрат на вычисления.
Литература:
- Богачёв, К. Ю. Основы параллельного программирования: учебное пособие / К. Ю. Богачёв. — 5-е изд. — Москва: Лаборатория знаний, 2024.
- Воеводин В. В., Параллельные вычисления / В. В. Воеводин, Вл.В. Воеводин. — СПб.: БХВ-Петербург, 2002.
- Гергель, В. П. Теория и практика параллельных вычислений. — М., 2007.
- Федотов И. Е. Некоторые приемы параллельного программирования. — Москва, 2008.
- Хьюз К., Хьюз Т. Параллельное и распределенное программирование на С++. Москва 2004.
- Dhall, S.K., 1977. Scheduling periodic-time-critical jobs on single processor and multiprocessor computing systems. University of Illinois at Urbana-Champaign.
- Matloff N. Programming on Parallel Machines. // University of California, 2008.

