Для решения проблемы отсутствия готовых данных и сложности поиска оптимального значения оценки рисков информационной безопасности в данной статье применяется новый метод информационной меры и нечеткой кластеризации в оценке рисков информационной безопасности. Новый метод определяет количество факторов риска всех данных и зависимость степени безопасности при вычислении взаимной информации. Затем поиск оптимального значения для каждой степени риска определяется как центр точек по К-means алгоритму кластеризации, используется К-meansалгоритм кластеризации для классификации данных. Этот метод прост в реализации, легко рассчитывается и позволяет избежать проблемы чувствительности к начальному значению, нелинейности и сложности оценки рисков информационной безопасности. Экспериментальные результаты показывают эффективность данного метода.
Ключевые слова: информационная безопасность, оценка рисков, информационные измерения, нечеткая кластеризация.
1. Введение
С развитием Internet-технологий и электронной коммерции с каждым днем появляется все больше угроз безопасности информации. Сегодня организации все чаще используют информацию в бизнес-процессах, для облегчения управленческих решений и ведения бизнеса. Зависимость от информации в бизнес-среде крайне велика, где множество торговых операций осуществляется в электронном виде через Internet. Такая информационная зависимость привела к существенному увеличению влияния уровня безопасности информационных систем на успех, а иногда и просто возможность ведения бизнеса. Поэтому безопасность информационных систем является одним из важнейших вопросов, который привлекает большое внимание со стороны аналитиков, инженеров и других специалистов в области информационно безопасности.
Оценка рисков начала использоваться на атомных электростанциях Европы и Америки в начале 1960-х годов, а в последствии развивалась и применялась аэрокосмической инженерии, химической промышленности, охране окружающей среды, здравоохранении, спорте, развитии национальной экономики и многих других областях. В информационной безопасности методики оценки рисков появились с целью прогнозирования возможного ущерба, связанного с реализацией угроз, и соответственно оценки необходимого размера инвестиций на построение систем защиты информации.
Четкой методики количественного расчета величин рисков как не было, так и нет. Это связано в первую очередь с отсутствием достаточного объема статистических данных о вероятности реализации той или иной угрозы. В результате наибольшее распространение получила качественная оценка информационных рисков. Но как использовать результаты такой оценки? Как рассчитывать возможный ущерб и размер необходимых инвестиций для предотвращения реализации рисков?
До сих пор ведутся споры на тему оценки информационных рисков или экономического обоснования инвестиций в информационную безопасность. В настоящее время идет активное накопление данных, на основании которых можно было бы с приемлемой точностью определить вероятность реализации той или иной угрозы. К сожалению, имеющиеся справочники опираются на зарубежный опыт и потому с трудом применимы к российским реалиям.
В настоящее время основные научные достижения в области оценки рисков информационной безопасности включают известные методы: OCTAVE-метод [1], CRAMM5 [2], PRA [3], и т. д. Но эти стандарты и методы имеют некоторые недостатки, некоторые из них являются только качественными методами анализа, некоторые — только количественными, громоздкими для реализации. Оценка рисков информационной безопасности имеет некоторые характеристики, такие как нелинейность, сложность применения, характеристики, обусловленные некоторыми ограничениями на использование традиционных моделей для проведения оценки рисков информационной безопасности. Эти традиционные методы оценки массу субъективных проблем и неясностей, поэтому они более сложны в применении.
Данная статья предлагает новый метод оценки рисков информационной безопасности, основанный на комбинации вычисления взаимной информации и К-means алгоритма кластеризации. Для того чтобы добиться эффективной оценки уровня рисков информационной безопасности, новый метод определяет количество факторов риска всех данных и зависимость степени безопасности при вычислении взаимной информации. Затем осуществляется поиск оптимального значения для каждой степени риска как центр точек К-means алгоритма кластеризации и используется К-means алгоритм кластеризации для классификации данных.
Статья построена следующим образом. Раздел 2 описывает риски системы информационной безопасности. Раздел 3 предлагает оценку рисков информационной безопасности на основе взаимной информации и K-means методе. Затем показаны экспериментальные результаты в разделе 4 и обобщение работы в разделе 5.
2. Риски системы информационной безопасности
Риск информационной безопасности определяется как произведение финансовых потерь (ущерба), связанных с инцидентами безопасности, и вероятности того, что они будут реализованы. Данное определение подходит при рассмотрении различных архитектур информационных систем.
Информация может существовать в различных формах. Она может быть написана на бумаге, храниться в электронном виде, пересылаться по почте или с использованием электронных средств, транслироваться на экране или обсуждаться в разговоре. Какие бы формы информация ни принимала, она всегда должна быть защищена соответствующим образом.
Оценка рисков информационной безопасности, с точки зрения управления рисками, анализ систематически подвергающихся угрозам и существующим уязвимостям информационных систем и технологий научными методами и средствами. Оценка потенциального ущерба в случае угрожающих событий проведена и выдвинуты контрмеры против угроз для предотвращения и урегулирования рисков информационной безопасности, а также контроль рисков на приемлемом уровне таким образом чтобы максимально обеспечить безопасность информации. Оценка рисков информационной безопасности состоит из трех основных этапов: идентификация угроз, идентификация уязвимостей, идентификация активов [4] (рис.1)
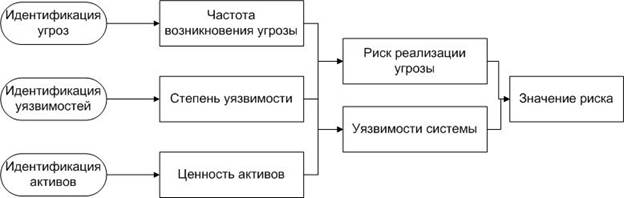
Рис.1. Элементы оценки рисков информационной безопасности
Процесс оценки риска информационной безопасности выглядит следующим образом:
1) Определение информационных активов, установление ценности активов;
2) Анализ угроз, определение вероятности угроз
3) Идентификация уязвимостей информационных активов, определение степени уязвимости
4) Вычисление вероятности наступления события по реализации угроз (использованию уязвимостей)
5) Сочетая важность информационных активов и возможность возникновения инцидентов, выполняется расчет значения риска информационной безопасности для информационного актива.
Проиллюстрируем вычисление риска с помощью формулы:
Riskvalue = R (A, T, V) = R (L (T, V), F (Ca, Va)), (1)
где R — функция вычисления риска,
A — активы,
T — угрозы,
V — уязвимости,
Ca — стоимость активов, принесенная инцидентом,
Va — степень уязвимости,
L — возможность угрозы привести к инцидентам с помощью уязвимостей,
F — потери, вызванные событиями безопасности.
Определение значения риска связано с результатами оценки риска и выработкой мер по контролю риска, поэтому это является важным и сложным этапом в процессе оценки риска. Это основной вопрос моего исследования.
В целях предотвращения несанкционированного доступа организации используют различные контрмеры для защиты своих активов. Но даже благодаря применению контрмер и управлению информационной безопасностью активы зачастую не в полной мере защищены от угроз из-за недостатка контроля.
Таким образом, оценка рисков является одним из важнейших шагов в управлении рисками инфо рационной безопасности. На практике оценка рисков информационной безопасности является довольно сложным и полным неопределенностей процессом [5]. Неопределенности, существующие в процессе оценки, являются основным фактором, влияющим на эффективность оценки риска информационной безопасности. Поэтому они должны быть приняты во внимание при оценке рисков. Однако большинство существующих подходов имеют некоторые недостатки по обработке неопределённости в процессе оценки.
3. Оценка рисков информационной безопасности на основе взаимной информации и k-means алгоритма кластеризации
В оценке рисков информационной безопасности основные элементы риска отражаются в активах системы, существующих угрозах и уязвимостях, а также анализ рисков оценивает уровень риска от оценки показателей, таких как частота угрозы, степень тяжести уязвимости, стоимость активов и т. д. Оценочные показатели имеют некоторые свойства значительной двусмысленности и неопределенности, поэтому обычные методы с трудом поддаются измерению. Кроме того, эти оценки показателей и уровней риска являются нелинейными и динамические изменяющимися, поэтом обычные методы так трудно перерабатывать. Новый метод оценки рисков не содержит данных проблем. Во-первых, мы используем метод нечеткой оценки для количественного измерения риска. Во-вторых, рассчитывается значение взаимной информации риска для обозначения зависимости степени риска и уровня риска. Данные были классифицированы по К-means алгоритму с оптимальными взаимными информационными данными в качестве исходных центров кластеров. Этот способ прост и содержит небольшое количество вычислений. Он позволяет избежать проблемы чувствительности к начальному значению, нелинейности и сложности оценки рисков информационной безопасности.
3.1. K-means алгоритм
Кластерный анализ является общей техникой для статистического анализа данных, которая стремится сгруппировать объекты подобного рода в отдельные категории. Это широко используется в математике, в социальных науках, маркетинге, биоинформатике и т. д. Кластерный анализ включает в себя ряд эвристических методов, в том числе К-means алгоритм и модель смеси.
Алгоритм K-means является непараметрическим подходом, направленным на классификацию объектов на К взаимоисключающих кластеров путем минимизации квадрата расстояния от объекта до его ближайшего центра.
Алгоритм разделяет данные на k кластеров Si (I = 1, 2, …, k). Кластер Si связан с представителем (центр кластера) Ci.
Обозначим множество точек данных через S = { Xm}, m =1, 2, …, N. N количество точек данных в наборе S. Пусть d (X, Y) будет искажением между любыми двумя из векторов X и Y.
Пусть Cmm будет ближайшим центром кластера Xm и dm = d (Xm, Cmm). Цель K-means кластеризации — найти множество центров кластеров SC {Cl}, таких, что искажения J определенные ниже, сведены к минимуму, где l = 1.. K. K — это количество кластеров.
![]() (2)
(2)
Основной процесс K-means кластеризации — это отображение заданного набора векторов в улучшенных через разделение точек данных. Оно начинается с начальным набором центров кластеров и повторяет это отображение процесса, пока критерий остановки не будет выполнен.
Итерации Ллойда K-means алгоритма кластеризации выглядят следующим образом:
1) Дано множество центров кластеров SCp = {Ci}, найти разбиение S; то есть S разделить на K кластеров Sj, где j = 1, 2, …, и Sj = {X / d (X, Cj) <= d (X, Cj) для всех i не равно j).
2) Вычислить центр тяжести для каждого кластера, чтобы получить новый набор кластеров SC p+1.
К-means алгоритм кластеризации кратко описывается следующим образом:
1) Начать с начальным набором центров кластеров SC0. Множество P=0.
2) C учетом множества центров кластеров SCp, выполнить итерацию Ллойда для создания улучшенного набора кластеров SCp+1.
3) Рассчитать среднее искажения J для SCp+1. Если оно изменилось на достаточно маленький объем после последней итерации, нужно остановиться. В противном случае установить р +1 → P и перейти к шагу 2.
Ближайший центр кластера определяется путем расчета расстояния между каждым центром кластера и точкой данных. В данной статье, функция расстояния принимает, xd)евклидово расстояние. Евклидово расстояние между точкой данных X = (x1, x2, …, xd) в степени t и центр кластера C = c1, c2, …, cd) в степени t определяется как
![]() (3)
(3)
Тем не менее, К-means алгоритм это процедура локального поиска и хорошо известно, что данный алгоритм страдает серьезным недостатком, что его производительность сильно зависит от начальных условий [6]. В нашем методе мы используем вычисление взаимной информации, чтобы решить эту проблему.
3.2. Модель оценки
Основная идея модели оценки риска информационной безопасности, основанной на вычислении взаимной информации и K-means алгоритме в следующем. Во-первых, определение количественной оценки риска с нечетким подходом к оценке, во-вторых, поиск оптимальных значений в каждом уровне риска с вычислением взаимной информации после количественной обработки и обработки на совместимость, в качестве исходных центров кластеров алгоритма кластеризации K-means. Модель структуры показан на рис. 2.
Рис. 2. Структура модели оценки
Как показано на рис. 2, уровни безопасности информационной системы разделены на четыре класса соответственно определенных как L1, L2, L3 и L4. L1 представляет собой минимальный уровень безопасности, L4 представляет собой самый высокий уровень безопасности. Есть 4 кластера в результатах K-means кластеризации, так что K = 4.
1) Формат информации исходных данных, полученных из информационной системы не в соответствии с нашим методом, должен быть обработан, чтобы быть векторной форме как требуется для нашего метода. Поскольку значения риска имеют свойство неопределенности, в этой статье мы используем нечеткий подход для предварительной оценки показателей риска информационной безопасности.
2) Обработка данных:
Данные, которые были введены в нашем алгоритме, делятся на два класса: подготовительные данные и тестовые данные. Основная польза подготовительных (обучающих) данных — обучение K-means алгоритма кластеризации. Это говорит о том, что алгоритм К-means кластеров с подготовительными данными нужен для поиска оригинальных кластеров и центров кластеров. Это процесс обнаружения (раскрытия) знаний. Затем K-means алгоритм кластеризации классифицирует данные с исходными кластерами и центрами кластеров. Для подготовки данных:
а) Вычислить значение взаимной информации между предварительно обработанными данных и дать четыре оптимальных набора точек в соответствии с уровнем риска L1, L2, L3 L4 для каждых обучающих данных. Взаимная информация (mutual information — MI) определяется как снижение неопределенности одной случайной переменной из-за знания о другом, или, другими словами, количество информации, которое одна случайная переменная содержит о другой.
Наша модель имеет набор данных, хранение оптимальных точек установлено в соответствии с уровнем риска L1, L2, L3 и L4, которые получены через экспертный анализ большого количество данных.
б) для каждого уровня риска, рассчитать значения взаимной информации между всеми данными, а затем вычислить сумму этих значений взаимной информации, которая получена на последнем шаге. Так мы можем получить среднее значение всей взаимной информации.
в) получить четыре средних значения взаимной информации соответствующих в указанном порядке для четырех уровней риска информационной безопасности. Затем искать четыре оптимальные точки, ближайших к средним значениям в качестве начальных центров кластеров К-means алгоритма кластеризации.
Для проверки данных, вычислить расстояние между каждым центром кластера и каждыми тестовыми данными, чтобы определить ближайший центр кластера (для присоединения), кластер с К-means алгоритмом, который уже обладает начальными центрами кластеров, сгенерировать новые результаты кластеризации.
3) Судьи изменяют результаты кластеризации или нет. Если метки некоторых данных в кластере изменены в новых результатах кластера, то это означает, что новый центр кластера может быть неправильным, неправильные центры кластеров могут быть вызваны ложным обнаружением курса. В целях обеспечения и повышения точности обнаружения, мы пересчитаем значение взаимной информации всех данных, чтобы найти оптимальные точки в качестве начальных центров кластера алгоритма К-means.
3.3. Предварительная нечеткая обработка
В оценке рисков информационной безопасности, оценка показателей риска не имеет четких свойств и неопределенностей, наш метод количественно оценивает риски информационной безопасности с нечетким подходом к оценке. Конкретные шаги заключаются в следующем:
1) корреляционный анализ активов, уязвимостей, угроз и отношения угрозы и уязвимости к выявлению риска информационной безопасности.
2) На основе нечеткого подхода к оценки, факторы риска создают множество U = {u1, u2, …, un}.
3) Создание набора оценки. Оценить различные факторы риска конфиденциальности и целостности активов, степень уязвимости, техническое содержание угрозы и другие аспекты. Эксперты дают обзор рисков различных факторов риска, каждый обзор рисков делится на m классов, набор оценок: V = {v1, v2, …, vm}.
4) Эксперт дает обзор рисков каждого фактора риска, создавая нечеткое изображение: f: U стрелка F (V), F (V) все нечеткое множество на V, ui стрелка f (ui), где ui= (ri1, ri2, …, rim) принадлежит F (V). Отображение функции f представляет собой фактор риска ui как вектор ui, прилагаемый к набору оценок (степень каждого обзора в наборе оценок). Установить риск R = {ri1, ri2, …, rim}, I = 1, 2, …, n, получим матрицу R.
5) Значение индекса в наборе оценок непосредственно влияет на степень риска, поэтому, важно учитывать вес каждой оценки индекса. Установить набор распределения весов как A = (a1, a2, …, an). Посредством нечеткого преобразования оператора, получим:
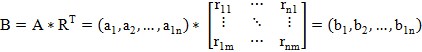 (4)
(4)
В представляет веса всех факторов риска при оценке. B отражает оценку вида фактора риска, значение которого находится в наборе (0,1).
3.4. Вычисление взаимной информации
Взаимная информация является важным понятием теории информации, которая измеряет статистическую зависимость между двумя переменными, то есть информация, которую одна переменная содержит о другой. Впервые она была предложена в качестве регистрационной меры в медицинской регистрации изображений в 1995 году независимо друг от друга учеными Viola и Wells. Это важное понятие в области теории информации, которая измеряет степень взаимозависимости между двумя сообщениями, широко используется в классификации текстов и функция сокращения. Взаимная информация также широко используется для установления одного из наиболее важных параметров.
Взаимная информация определяется как снижение неопределенности одной случайной переменной вследствие наличия знаний о другом, или, другими словами, количество информации об одной случайной переменной содержащейся в другой.
Мы используем меру взаимной информации как статистическую степень корреляции между значением фактора риска и уровнем риска, который определяется как:
![]() , (5)
, (5)
где
![]() ,
,
![]() — является атрибутом (конкретное значение факторов оценки риска),
— является атрибутом (конкретное значение факторов оценки риска),
![]() представляет собой количество различных значений фактора оценки риска во всех примерах данных,
представляет собой количество различных значений фактора оценки риска во всех примерах данных,
![]() представляет собой вероятность вида
представляет собой вероятность вида ![]() , а именно отношение числа появления
, а именно отношение числа появления ![]() во всех факторах оценки подготовительных данных и общего количества значений факторов оценки, больше
во всех факторах оценки подготовительных данных и общего количества значений факторов оценки, больше ![]()
p(d) = в /N — представляет собой вероятность подготовительных данных, которые относятся к уровню d (эта статья делит степень безопасности на 4 уровня, так что значение d может быть одним из ![]() .
.
![]() представляет условную вероятность
представляет условную вероятность ![]() ,
, ![]() представляет собой число выборочных данных, значения атрибута которых —
представляет собой число выборочных данных, значения атрибута которых — ![]() , и уровень риска принадлежит d, d представляет собой общее число выборочных данных, чей уровень риска принадлежит d.
, и уровень риска принадлежит d, d представляет собой общее число выборочных данных, чей уровень риска принадлежит d.
![]() — представляет собой вероятность появления
— представляет собой вероятность появления ![]() , в то время как данные с атрибутом
, в то время как данные с атрибутом ![]() принадлежат уровню риска d.
принадлежат уровню риска d.
Значение ![]() указывает на соответствующую степень
указывает на соответствующую степень ![]() и уровень риска d, тем больше значение, тем выше степень связи. Таким образом,
и уровень риска d, тем больше значение, тем выше степень связи. Таким образом, ![]() к привносит большой вклад в уровень d.
к привносит большой вклад в уровень d.
Предположим, оценка факторов риска учитывалось от четырех факторов, в том числе конфиденциальности и целостности активов, степень уязвимости и техническое содержание угрозы. Уровень защиты делится на четыре класса, ![]() представляет минимальный уровень безопасности,
представляет минимальный уровень безопасности, ![]() представляет собой максимальную безопасность. Мы выбираем восемь наборов нечетких данных для предварительной оценки, как показано в таблице 1.
представляет собой максимальную безопасность. Мы выбираем восемь наборов нечетких данных для предварительной оценки, как показано в таблице 1.
Таблица 1
Уровни безопасности
|
№ данных |
|
|
|
|
Уровень безопасности |
|
D1 |
0, 1 |
0,3 |
0,3 |
0,2 |
L1 |
|
D2 |
0,5 |
0,3 |
0,4 |
0,3 |
L2 |
|
D3 |
0,5 |
0,3 |
0,4 |
0,3 |
L2 |
|
D4 |
0,3 |
0,7 |
0,5 |
0,3 |
L4 |
|
D5 |
0,3 |
0,3 |
0,2 |
0,3 |
L2 |
|
D6 |
0,3 |
0,1 |
0,3 |
0,3 |
L1 |
|
D7 |
0,5 |
0,3 |
0,3 |
0,5 |
L3 |
|
D8 |
0,3 |
0,3 |
0,1 |
0,1 |
L1 |
Сначала мы подсчитаем количество значений для каждого атрибута., Затем вычисляем взаимную информацию для значений (0,1; 0,2, …) в атрибутах ![]() , … соответствующего уровня риска L1 следующим образом:
, … соответствующего уровня риска L1 следующим образом:
![]() (6)
(6)
3.5. Оценка рисков информационной безопасности на основе взаимной информации и K-means алгоритма
К-means алгоритм кластеризации является одной из основных алгоритмов кластерного анализа, которые используют итерационный метод для обновления. Конечный результат состоит в получении минимальной целевой функции и для достижения оптимального эффекта кластеризации. К-means алгоритм работает следующим образом. Во-первых, случайным образом выбираются k объектов данных из n данных в качестве исходных центров кластеров. Для остальных объектов, в соответствии с их сходством с центром кластера (расстояние) соответственно назначаем им наиболее похожую (представленные ??центром кластера) кластеризацию, а затем пересчитываем центра кластера для каждого нового приобретенного кластера. Алгоритм завершается, когда на какой-то итерации не происходит изменения кластеров. Это происходит за конечное число итераций, так как количество возможных разбиений конечного множества конечно.
Традиционный алгоритм К-means случайного выбора начальных центров кластеров с различными начальными значениями результатов может легко колебаться. Это вызвано обнаружением значительного отклонения результатов и необходимости большего количества итераций.
В нашем методе, значение взаимной информации используем в качестве исходных центров кластеров, так что в начале кластеризации центры кластеров являются оптимальными значениями. Поэтому наш метод может преодолеть недостатки чувствительности к начальному значению, а также уменьшает количество итераций. За функцию определения расстояния принимается евклидова функция.
Для приведенных подготовительных данных, формы данных предварительно обработаны как показано в Таблице 1. Для данных Di мы можем вычислить ![]() , что представляет собой степень вклада всех атрибутов bi в уровень Li. Li представляет уровень соответствующего класса Di.
, что представляет собой степень вклада всех атрибутов bi в уровень Li. Li представляет уровень соответствующего класса Di.
![]() , (7)
, (7)
где ![]() — это вес, соответствующий каждому атрибуту, направленный на приведение соотношения атрибута в
— это вес, соответствующий каждому атрибуту, направленный на приведение соотношения атрибута в ![]() . Чем больше
. Чем больше ![]() тем больший вклад имеет
тем больший вклад имеет ![]() в
в ![]() .
.
Определим среднее значение взаимной информации всех данных, степень которой принадлежит ![]() :
:
![]() , (8)
, (8)
где ![]() представляет количество данных, которые принадлежат уровню
представляет количество данных, которые принадлежат уровню ![]() .
. ![]() представляет собой среднее значение вклада данных в
представляет собой среднее значение вклада данных в ![]() , которые принадлежат уровню
, которые принадлежат уровню ![]() .
.
4. Эксперимент
Экспериментальные образцы взяты из информационных систем компании из сферы деятельности электронной коммерции. В нашем эксперименте мы разделили три основных фактора (идентификация угроз, идентификация уязвимостей, идентификация активов), которые оказывают влияние на оценку рисков информационной безопасности в 10 конкретных факторах:
- информация украдена, удалена или потеряна;
- сетевые ресурсы уничтожены;
- ложное использование и фальсификация информации;
- прерывания работы и запреты;
- аппаратных дефекты;
- сетевые уязвимости;
- утечка данных;
- вмешательство в связь;
- восстановление обслуживания;
- прерывание обслуживания.
Оценим факторы риска экспертно, присвоим вес каждому фактору в качестве входных данных.
Разделим результаты оценки на четыре категории: высокой безопасности, средней безопасности, подозрительно и опасно, соответственно, как L1, L2, L3 и L4.
Данные включают в себя подготовительные данные и тестовые данные. Для подготовительных данных: каждые такие данные могут быть выражены как 1 * 10-мерный вектор, то есть ![]() . Для эксперимента выберем 200 подготовительных данных, как показано в таблице 2.
. Для эксперимента выберем 200 подготовительных данных, как показано в таблице 2.
Данные в таблице 2, которые прошла через нечеткую предварительную обработку в качестве подготовительных данных, были рассчитаны по 10 показателям безопасности каждого образца. И 100 тестовых данных, как показано в таблице 3, также списком по 10 показателям безопасности. Все данные разделены на 10 групп, и каждая группа включает в себя 20 обучающих данных и 10 текстовых данных для исследования нашего алгоритма.
Таблица 2
Подготовительные данные
|
№ данных |
|
|
… |
|
Уровень безопасности |
|
D1 |
0, 4 |
0,3 |
… |
0,4 |
L3 |
|
D2 |
0,5 |
0,3 |
… |
0,3 |
L2 |
|
D3 |
0,5 |
0,3 |
… |
0,3 |
L2 |
|
D4 |
0,3 |
0,7 |
… |
0,3 |
L4 |
|
D5 |
0,3 |
0,3 |
… |
0,3 |
L2 |
|
D6 |
0,3 |
0,1 |
… |
0,3 |
L1 |
|
D7 |
0,5 |
0,3 |
… |
0,5 |
L3 |
|
… |
… |
… |
… |
… |
… |
Таблица 3
Тестовые данные
|
№ данных |
|
|
… |
|
Уровень безопасности |
|
D1 |
0, 6 |
0,3 |
… |
0,4 |
L3 |
|
D2 |
0,3 |
0,3 |
… |
0,3 |
L1 |
|
D3 |
0,5 |
0,3 |
… |
0,4 |
L1 |
|
D4 |
0,4 |
0,7 |
… |
0,3 |
L4 |
|
D5 |
0,4 |
0,3 |
… |
0,3 |
L2 |
|
… |
… |
… |
… |
… |
… |
Точность обнаружения нашего метода достигла 98 % для данных в таблице 3. Экспериментальные результаты показывают, что наш метод эффективен, кроме того, имеет меньше вычислений, чем традиционные методы. Также наблюдается высокая скорость вычислений.
Наша оценка риска метод может более точно оценить уровень риска информационной безопасности, а значит более надежно защититься от реализации рисков.
5. Заключение
Для того чтобы решить проблему оценки рисков информационной безопасности, связанную со сложностью определения оптимальных значений, в данной статье предложен новый метод оценки рисков информационной безопасности, основанный на вычислении взаимной информации и K-means алгоритме кластеризации, позволяющем эффективно оценивать уровни риска информационной безопасности.
Метод определяет степень количественной зависимости между факторами риска и уровнем информационной безопасности с вычислением взаимной информации.
На каждом уровне риска, определяются оптимальные точки как начальные центры кластеров по алгоритму К-means, затем алгоритм кластеризации К-means классифицирует данные. Наш метод может динамически регулировать центр кластера в соответствии с результатами кластеризации и вычисление значения взаимной информации.
Этот метод легко применять, он имеет меньше вычислений, чем традиционные методы. Метод позволяет предотвратить чувствительность к входным данным, нелинейность, сложность и другие проблемы оценки рисков информационной безопасности. Экспериментальные результаты также показывают превосходность метода.
Литература:
1. Maiwald E. Netwok Secuity: A Begginner’s. The McGraw-Hill Companies, Inc,2001.
2. ISO/IEC 17799. Information Technology-Code of practic for information security management.2000.
3. MnSCU. Security Risk Assessment-Applied Risk Management Minnesota State Colleges & Universities, 2002, с.7.
4. А. Астахов. Искусство управления рисками. GlobalTrust. 2009.
5. R. L. Winkler, Uncertainty in probabilistic risk assessment, Reliability Engineer- ing and System Safety 54 (2–3) (1996), с. 127–132.
6. Dang Depeng, Meng Zhen. Assessment of information security risk by support vector machine. Journal of Huazhong University of Science and Technology(Natural Science Edition), 2010, 3(38), с.46–49.

