In this article, the authors compare machine learning algorithms in the task of analyzing text tonality
Keywords: sentiment analysis, sentiment analysis of text, sentiment analysis, machine learning methods, classification methods, binary classification, deep learning.
Introduction
Text tonality analysis is a task of computer linguistics, which consists of determining the emotional coloring (tonality) of a text and, in particular, identifying the emotional evaluation of the authors in relation to the objects described in the text. Currently, the following are mostly used to identify sentiment in a text:
1) The rule-based or linguistic analysis approach and dictionaries. This approach is based on the use of dictionaries with templates prepared by hand, containing emotionally important words and phrases with their emotional evaluations. Using this approach, the text is searched for intersections with the dictionary. Then, based on the sum of the scores, the intersections found determine the tone of a given text. This approach shows good results in some areas. The main drawback of this approach is the complexity of preparing dictionaries, you need to know the subject area for which the dictionary is compiled. The second drawback is poor scalability, because of which we cannot use the same dictionary for different fields. The same terms in different fields can contribute different weight to the degree of emotional coloring [1].
2) Machine learning approach. The essence of this approach is that, first, the classifier is trained on pre-labeled data, which are then used to classify new texts. The methods of this approach will be discussed in more detail in this article.
3) Hybrid approach, combining rule-based and dictionary-based approaches and machine learning-based approaches. A number of studies show that this approach can improve the quality of classification, but this approach is the most time consuming. The purpose of this article is to explore state-of-the-art machine learning methods for solving this problem of identifying sentiment in natural language text. Both traditional machine learning methods and currently popular deep learning methods. The results of this study are planned to be used for further research in the field of text tone detection.
Machine Learning Methods
The text presents machine learning and deep learning methods for sentiment analysis [2]. The naive Bayesian classifier is a simple, probabilistic classifier based on Bayes theorem with independent feature assumptions. Despite its limitations, it can show good results in text classification with small data requirements and ease of implementation [3].
Maximum entropy method is a probabilistic classifier that maximizes the chosen measure of uncertainty for certain information about the environment. It requires a small amount of data for training and is easy to implement, similar to the naive Bayesian classifier.
Decision trees are tree-like structures with attributes on which class probability distributions depend and class probability values on the leaves. They are easy to interpret and require minimal data preprocessing, but are prone to overfitting. Therefore, decision tree ensembles, such as random forests or gradient boosting, are more commonly used.
Random forest is a collection of decision trees that are combined to form an efficient classifier. However, if there are many features, the trees become very deep and building them takes a long time.
Gradient boosting is a machine learning method that improves the model at each stage using simple models like shallow decision trees. However, the limitation is that each tree can only consider a small subset of features, making it challenging to capture the full complexity of the data. As a result, using many trees may not guarantee acceptable quality.
Logistic regression is a linear classifier that uses a logical curve to evaluate the probability of objects belonging to a class based on a set of attributes. It's commonly used for regression and classification problems and often involves regularization to prevent overfitting. Although it's popular and yields good results, it requires careful feature pre-processing and selection [4].
The reference vector method is a linear machine learning algorithm for classification and regression. It finds a hyperplane that separates two classes of training examples and is one of the most effective methods for text classification. Linear models scale well, work with a large number of features, and are used in determining the tone of texts.
1) A corpus of movie reviews included in the NLTK library, 2,000 texts, averaging 3,500 characters per text.
2) Corpus from SentiWordNet lexical semantic thesaurus, 2000 texts, 150 characters per text on average.
AUC — the area under the ROC-curve (error curve) was used as a metric of the method efficiency. The authors trained several models, selecting different parameters to achieve the best results. Before this, data were preprocessed and trait selection was done. The best results for different machine learning methods are shown below in Figure 1.
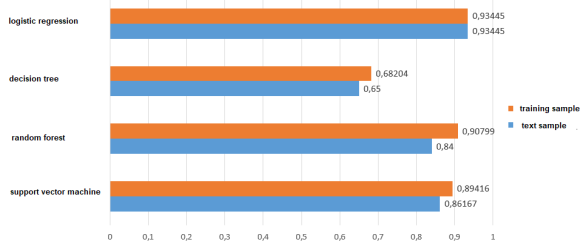
Fig. 1. Results of different machine learning methods
Another study uses datasets containing product reviews from an online store as input data. The accuracy metric is the ratio of correctly predicted items to the total number of items in the dataset. In this study, the following results were obtained, shown in Figure 2.

Fig. 2. Results of accuracy estimation of machine learning methods
As you can see among traditional machine learning methods, the best results show linear models: logical regression and support vector method. Random forests are also quite good. But the performance of traditional methods strongly depends on the amount and quality of training data [5]. In addition, the accuracy largely depends on the choice of features, which is a fairly time-consuming task. The quality of the analysis of the tone of the text, which do not follow the rules and grammar of the language, for example, messages on social networks, is often quite low. In this regard, we can conclude that pre-processing of data and careful selection of features is necessary.
Neural Networks
Deep learning is a popular machine learning technique that uses non-linear transformations and multi-layered architectures to extract «hidden features» from data [6].
Artificial neural networks model biological neural networks. They process natural language, including text tone. Configuring them is challenging, requiring determining hidden layers, activation functions, and error thresholds, plus large amounts of training data and time. However, neural networks can select features in data without human input and identify complex dependencies. They can return accurate results even with incomplete or distorted data and adapt to different problem variants. Convolutional and recurrent neural networks are the most effective for textual tonality analysis [7].
Convolutional Neural Networks (CNNs) were first used for image recognition but have been successful in other fields, including text classification. They use a convolution operation that allows them to pick up sentiment information from adjacent words. CNNs have been shown to outperform other algorithms in text tone analysis in some tests [8].
Recurrent neural networks (RNNs) process text, including tone analysis, with feedback to remember and reproduce sequences of reactions to one stimulus. They weigh both current and previous input data, with each word affecting the weights of other layers in the sentence. A study compared RNNs with linear models, showing the best results. It compared convolutional neural networks and logistic regression for tone determination in Twitter messages, measuring accuracy. The results are presented in Figure 3.
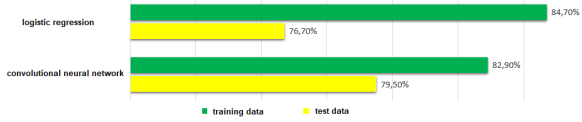
Fig. 3. Results of comparison of convolutional neural networks and logical regression
As you can see the convolutional neural network shows better results. But linear models have an advantage over convolutional neural networks in the learning time of 45 seconds against 6 hours. So if the training time is not a priority and there is a large amount of training data available, it is better to give preference to artificial neural networks [10].
Comparison of different recurrent and convolutional neural network architectures. The evaluation is done on a dataset containing movie reviews, and accuracy is used as a metric. The result is presented in figure 4.

Fig. 4. Comparison of accuracy of neural network architectures
Among deep learning methods in the task of analyzing the tone of the text, recurrent neural networks are more proven. But in some tasks convolutional neural networks can also show good results that surpass recurrent neural networks.
Conclusion
This article summarizes traditional and deep learning methods for text tonality analysis, with future work planned to evaluate deep learning methods and compare traditional and deep learning methods on different datasets. The ultimate goal is to develop methods and algorithms for analyzing the tonality of extremist statements on the Internet.
References:
- Bolshakova, E. I. Automatic text processing in natural language and data analysis / Moscow: HSE Publishing House, 2017. — 269 p.
- Vorontsov, K. V. Additive regularization of thematic models of collections of text documents // Reports of the Russian Academy of Sciences. — 2014. — № 3. — p. 268–271.
- Vladimir Vyugin: Mathematical foundations of machine learning and forecasting / Moscow: ICNMO Publishing House, 2018. — 384 p.
- Peskisheva T. A. Methods of analyzing the tonality of texts in natural language // Society. The science. Innovations (NPK-2017). — 2017. — pp. 1730–1742.
- Henrik Brink, Joseph Richards. Machine learning. Moscow: St. Petersburg Publishing House, 2020. — 545 p.
- Key points in the development of convolutional neural networks / Kuraeva E. S. // Young scientist. M., 2019, Issue 50, pp. 19–20.
- Aggarval Ch. Neural networks and deep learning: a training course. Moscow: Dialectics-Williams Publishing House, 2020, 752 p.
- Saetova L. G., Gorokhov M. M. Neural network and regression: description of linear regression in neural networks// Society. The science. Innovations (NPC-2021). — 2021. — pp. 1517–1532.
- Haikin S. Neural networks. Full course. Moscow: Williams Publishing House, 2018, 1104 p.
- Amit Konar, Aruna Chakraborty. Emotion recognition: An approach to pattern analysis. M.: Wiley, 2015. — 584 p.

