В данной статье наглядно и подробно рассмотрен пример работы с библиотекой Tesseract ORC, создана программа для распознавания текста с фото.
Ключевые слова: tesseract, OCR, OpenCV, оптическое распознавание, python.
OCR — оптическое распознавание символов. Другими словами, системы оптического распознавания символов преобразуют двумерное изображение текста, которое может содержать машинно-напечатанный или рукописный текст, из его графического представления в машиночитаемый текст.
Оптическое распознавание символов остается сложной проблемой, когда текст встречается в неограниченных средах, таких как естественные сцены, из-за геометрических искажений, сложного фона и разнообразных шрифтов.
В этой статье будет объяснена технология, лежащая в основе наиболее часто используемого Tesseract Engine, который был обновлен с учетом последних исследований в области оптического распознавания символов. Эта статья также будет служить руководством по реализации OCR в Python с использованием движка Tesseract. Tesseract — это бесплатное программное обеспечение оптического распознавания символов с открытым исходным кодом и большой базой языковых и символьных моделей. Данная библиотека использует нейронные сети для поиска и распознавания текста на изображениях. Программа ищет шаблоны в пикселях, буквах, словах и предложениях.
Python-tesseract — это «движок» оптического распознавания символов (OCR) для Python.
Tesseract ищет шаблоны в пикселях, буквах, словах и предложениях, использует двухэтапный подход, называемый адаптивным распознаванием. Требуется один проход по данным для распознавания символов, затем второй проход, чтобы заполнить любые буквы, в которых он не был уверен, буквами, которые, скорее всего, соответствуют данному слову или контексту предложения.
Первое, что необходимо сделать, то это выполнить установку Tesseract ORC. Установка Tesseract удобна на Маке и Линукс. Если вы на Windows, то придется выполнить на одно движение больше.
С самой программой никак не придется взаимодействовать, а лишь скопировать её расположение.
С самого начала написания кода следует подключить предустановленные библиотеки.
#Import pytesseract || #import Cv2
Далее необходимо указать программе на месторасположение файла
img = cv2.imread('C:\\Users\\Vlad\\Downloads\\123.png')
По умолчанию OpenCV хранит изображения в формате BGR, а поскольку pytesseract принимает формат RGB,
Нам нужно преобразовать из BGR в формат режим RGB:
# Img_rgb = cv2.cvtColor (img_cv, cv2.COLOR_BGR2RGB)
Для возможности распознавания различных языков (по умолчанию — английский), следует изменить функцию lang, принадлежащию классу image_to_string
#pytesseract.image_to_string(img, config=config, lang='rus+eng')
Так же можно выбрать в каком формате нам выдаст распознанный текст.
# Получить PDF-файл с возможностью поиска
pdf = pytesseract.image_to_pdf_or_hocr ('test.png', extension = 'pdf')
с open ('test.pdf', 'w + b') как f:
f.write (pdf) # тип pdf по умолчанию — байты
# Получить вывод HOCR
hocr = pytesseract.image_to_pdf_or_hocr ('test.png', extension = 'hocr')
# Получить вывод ALTO XML
xml = pytesseract.image_to_alto_xml ('test.png')
Поддержка изображений OpenCV / объектов массива NumPy.
Если же хотим на самой картинки выделять слова и формировать надпись, то надо бует дописать следующие функции:
Для начала нужно будет применить метод «image_to_date» — он возвращает найденные слова и их координаты.
Далее следует создать цикл для перебора списка и выводить по одному элементу: for i, el in enumerate(data.splitlines()):
Поскольку первый элемент — это лишь названия полей, его можно отсечь: if i == 0 || continue
Каждый элемент будем разбивать по пробелу, для разбивки строки используем метод split: el = el.split()
Теперь создаем переменные для хранения координат слова, его ширины и высоты.
x, y, w, h = list(map(lambda x: int(x), el [6:10]))
Для рисования на картинки используем библиотеку OpenCV и метод rectangle, в него указываем само фото, координаты, где мы будем рисовать, ширину и высоту и добавляем координаты, чтобы получился прямоугольник, а также указываем цвет обводки и толщину.
cv2.rectangle(img, (x, y), (w + x, h + y), (255, 0, 0), 1)
Чтобы около каждой обводки была выведена надпись, которую мы получили с помощью нашей программы, используем метод «putText» он принимает параметры: фото, текст, координаты, формат шрифта, его размер, цвет и жирность.
cv2.putText(img, el [11], (x+x, y-20), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 1)
Итоговый код программы и результат ее работы представлены на рисунках 1–3.

Рис. 1. Итоговый код программы

Рис. 2. Изображение, которое было загружено в программу

Рис. 3. Графическое отображение текста на изображение
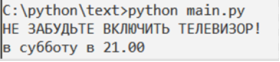
Рис. 4. Консольное отображение выполнения программы
Python на текущий момент, бесспорно, лидер в OCR. Программу по считыванию текста можно всегда дополнить благодаря использованию различных функций OpenCV. Библиотека Tesseract вместе с OpenCV на сегодняшний день является одним из самых простых и удобных способов распознавания текста с изображений.
Литература:
- Документация “Tesseract” // [Электронный ресурс]. Точный адрес: https://en.wikipedia.org/wiki/Tesseract

