





Ключевые слова: IDS, Cyber Security Alerts, Sequential Pattern Mining, SPMF
Глоссарий
Интеллектуальный анализ данных (en. data mining; рус. добыча данных, глубинный анализ данных) — собирательное название, используемое для обозначения совокупности методов обнаружения в данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности [1].
Добыча последовательностных паттернов (en. sequential pattern mining) — это часть интеллектуального анализа данных, связанная с поиском статистически значимых шаблонов (паттернов) в данных, где значения можно представить в виде последовательности [2].
Системы детекции вторжений (IDS) используются для сбора информации о сетевой активности и распознавания её как вредоносной или нет. В данном исследовании от компании N (в соответствии с политикой конфиденциальности компании, название компании и сами данные раскрывать нельзя) были получены данные о событиях IDS в виде лог-файлов в формате LEEF (Log Event Extended Format) [3]. Причем заранее известно, что в логах содержатся не все события, связанные с сетевой активностью, а только те, в которых IDS обнаружила признаки аномального поведения. При этом также известно, что в данных событиях большой процент ложных срабатываний. Поэтому появляется задача получения алгоритма, помогающего уменьшить процент ложных срабатываний у IDS.
Существует несколько направлений определения аномалий в событиях IDS [4], основанные на:
– Определении допустимого порога — в этом случае основные атрибуты поведения пользователя и системы выражаются в количественных терминах;
– статистических метриках;
– метриках, основанных на правилах;
– других метриках, включая нейросети, генетические алгоритмы и модели иммунных систем.
В современных коммерческих IDS используются только первые две технологии. В данной работе всё внимание уделено подходу, основанному на интеллектуальном анализе данных, а точнее на добыче последовательностных паттернов. Предполагается, что в атаках хакеров есть последовательность действий, которую можно обнаружить в логах IDS с помощью поиска последовательностных паттернов.
В исходных данных содержится большое количество событий с меткой о возможной уязвимости. С помощью анализа последовательностных паттернов хочется понять, связаны ли те или иные уязвимости, и если да, то в какой последовательности.
Данная работа базируется на статье [5], где авторы исследуют возможность применения последовательных паттернов и правил связей для анализа событий кибербезопасности. Для этого они используют библиотеку SPMF [6], содержащую большое количество алгоритмов для исследования данных.
1 Библиотека SPMF
Для получения паттернов были использованы алгоритмы из библиотеки SPMF. Далее приведено краткое описание библиотеки, входных и выходных данных для алгоритмов.
SPMF — это библиотека интеллектуального анализа данных с открытым исходным кодом, написанная на Java, специализирующаяся на добыче паттернов [6]. На момент написания статьи в этой библиотеке содержится реализация 150 алгоритмов интеллектуального анализа данных для поиска последовательностных паттернов, правил, наборов элементов и т.п.
Для работы алгоритмов требуются данные в формате SPMF database (далее база данных). В данной работе в основном использовался формат IBMGenerator database [7]. Пример преобразования последовательности к базе данных в формате IBMGenerator представлен ниже (Таблица 1).
Таблица 1
Пример преобразования последовательности к базе данных
|
Исходные четыре последовательности |
Последовательности в виде базе данныхв формате IBM-Generator |
|
1,2,3,4 5,6,7,8 5,6,7 1,2,3 |
1 -1 2 -1 3 -1 4 -1 -2 5 -1 6 -1 7 -1 8 -1 -2 5 -1 6 -1 7 -1 -2 1 -1 2 -1 3 -1 -2 |
База данных — бинарный файл, состоящий из целых чисел. Каждая строка представляет из себя одну последовательность. Положительные числа представляют из себя элементы последовательности. Число «-1» является разделителем набора элементов, а число «-2» является концом последовательности.
После обработки последовательностей алгоритмом, данные представляются в следующем виде (Таблица 2). Каждая строка в файле уже рассматривается как паттерн. В данном примере, первая строка из выходного файла интерпретируется следующим образом: паттерн, состоящий из элемента «4», за которым следует элемент «3», за которым следует элемент «2» встречается в базе данных 2 раза (параметр SUP).
Таблица 2
Пример входных и выходных данных алгоритма
|
Входные данные для алгоритма |
Выходные данные алгоритма |
|
4 -1 3 -1 2 -1 -2 5 -1 7 -1 3 -1 2 -1 -2 5 -1 1 -1 3 -1 2 -1 -2 4 -1 3 -1 2 -1 1 -1 -2 |
4 -1 3 -1 2 -1 #SUP: 2 5 -1 7 -1 3 -1 2 -1 #SUP: 1 5 -1 1 -1 3 -1 2 -1 #SUP: 1 4 -1 3 -1 2 -1 1 -1 #SUP: 1 |
2 Методы поиска последовательностных паттернов
Ниже приведено краткое описание использовавшихся методов.
Sequential pattern mining — метод поиска наиболее часто встречающихся последовательных паттернов (подпоследовательностей), которые часто встречаются во входной базе данных. У этого метода есть параметр Min Support — пороговое значение, выраженное в процентах. Если частота появления паттерна в базе данных больше порогового значения, то он будет показан в результатах.
Top-K sequential patterns — метод поиска последовательных паттернов, где в качестве параметра выступает не процентное соотношение паттернов, а точное число.
Closed sequential pattern mining — это оптимизированный метод поиска наиболее часто встречающихся паттернов, который фильтрует результаты, содержащиеся в других результатах.
Sequential generator pattern mining — это еще один оптимизированный метод поиска наиболее часто встречающихся паттернов, который фильтрует результаты, содержащиеся в других результатах.
Maximal sequential pattern mining— это еще один оптимизированный метод поиска наиболее часто встречающихся паттернов, целью которого является сокращение количества результатов.
Список выбранных алгоритмов из библиотеки SPMF для каждого метода представлен ниже (Таблица 3).
Таблица 3
Методы и алгоритмы
|
Метод |
Алгоритм |
|
Sequential pattern mining |
CM-SPADE |
|
Top-K sequential patterns |
TKS |
|
Closed sequential pattern mining |
CM-ClaSP |
|
Sequential generator patterns mining |
VGEN |
|
Maximal sequential pattern mining |
VMSP |
3 Описание и особенности входных данных
Исходные логи состоят из 26 полей с информацией о событии IDS. Стоит отметить, что IDS сохраняет не всю информацию о событии, и значения некоторых полей в событиях отсутствовали. Для анализа были отобраны 540 тыс. событий, которые произошли в один день, и в которых присутствуют все необходимые поля. Диаграмма зависимости количества событий, отобранных IDS, в зависимости от времени суток представлена ниже (Рисунок 1).
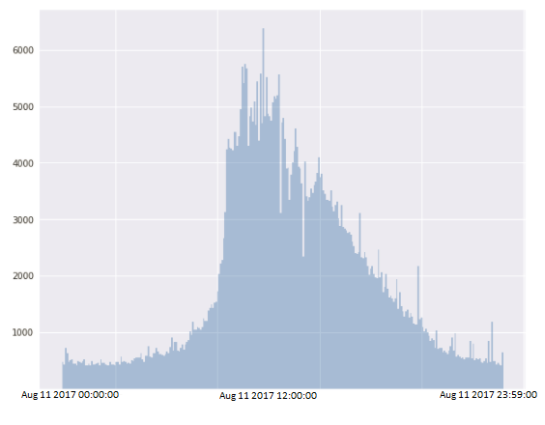
Рис. 1. Диаграмма зависимости количества событий, от времени суток
В исходных логах нет четкой категоризации событий, но есть поле Vulnerability, которое содержит в себе один или несколько номеров уязвимостей (к примеру: CVE-2010-0740 или BID-27638). Количество различных уязвимостей было более 1000, и алгоритмы анализа данных не смогли бы найти устойчивые паттерны. Поэтому для классификации событий было решено сопоставить каждой уязвимости её тип с сайта National Vulnerability Database [8]. Итоговое распределение данных по категориям представлено ниже (Рисунок 2).
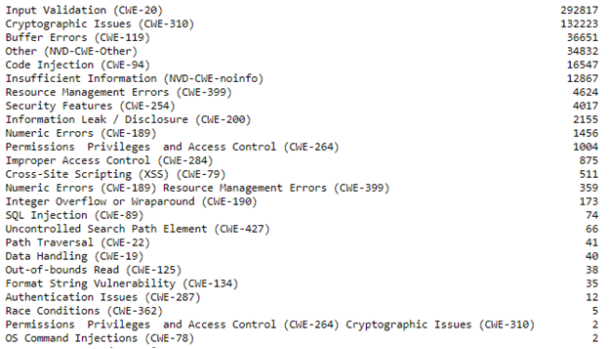
Рис. 2. Категория событий и число событий с данной категорией
В результате предобработки были отобраны или сгенерированы следующие поля:
– Уникальный идентификатор события;
– Время обнаружения события;
– Категория уязвимости события;
– IPv4-адрес отправителя;
– Протокол отправителя;
– Порт отправителя;
– IPv4-адрес получателя;
– Протокол получателя;
– Порт получателя.
С помощью [9] были сгенерированы различные базы данных (Таблица 4), где в качестве элементов последовательности выступали в различных комбинациях IP-адрес отправителя, порт отправителя, IP-адрес получателя, порт получателя. Из дальнейшего рассмотрения было решено исключить базы данных под номерами 2, 6 и 8 т. к. количество уникальных элементов больше половины количества исходных событий и не принесёт никаких значимых результатов.
Таблица 4
Сгенерированные базы данных
|
№ |
База данных, где в качестве элемента выступает |
Количество уникальных элементов |
|
1 |
IP-адрес отправителя |
58647 |
|
2 |
IP-адрес и порт отправителя |
352539 |
|
3 |
IP-адрес получателя |
11676 |
|
4 |
IP-адрес и порт получателя |
18173 |
|
5 |
IP-адрес отправителя, и IP-адрес получателя |
84666 |
|
6 |
IP-адрес и порт отправителя, и IP-адрес получателя |
461746 |
|
7 |
IP-адрес отправителя, и IP-адрес и порт получателя |
90865 |
|
8 |
IP-адрес и порт отправителя, и IP-адрес и порт получателя |
467139 |
Общая схема получения и анализа паттернов представлена ниже (Рисунок 3). Сначала исходные логи предобрабатывались, потом создавались различные базы данных, потом эти базы данных подавались на вход алгоритмам. Результаты работы алгоритмов дополнительно фильтровались и анализировались.
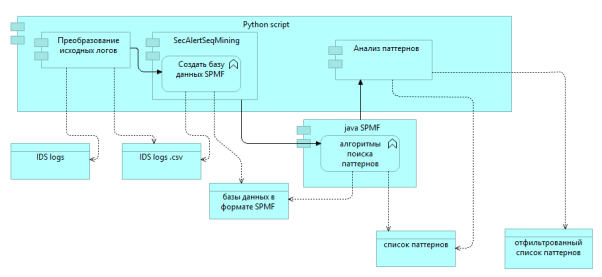
Рис. 3. Схема получения и анализа паттернов
4 Результаты
4.1 Сравнение результатов работы алгоритмов
Для каждой из сгенерированных баз данных были протестированы алгоритмы из главы 2. Стоит отдельно отметить, для алгоритмов, где присутствует параметр min support, он выставлялся в 1 %. Для алгоритма TKS количество паттернов было выставлено в 50.
- В результатах алгоритмов присутствует избыточность, проявляющаяся в форме повторения одного и того же элемента, который иногда чередуется с другим элементом (в среднем около 95 % всех паттернов избыточны). Порой результаты состояли только из паттернов, в которых все элементы одинаковые.
- По количеству паттернов, состоящих из разных элементов, алгоритмы CM-SPADE, VGEN и VMSP справились одинаково хорошо. Хуже справился TKS, еще хуже CM-ClaSp.
- Среди всех исследуемых методов наилучшим можно считать VMSP — при одинаковом параметре min support этот алгоритм показывает те же результаты, что и другие алгоритмы, но при этом он очень хорошо фильтрует избыточные паттерны.
- База данных, где в качестве элементов выступали IP-адрес получателя, и база данных, где в качестве элементов выступали IP-адрес получателя + порт получателя, не дали никаких значимых результатов. Все паттерны, из этих баз данных состояли исключительно из одних и тех же элементов, что эквивалентно обычной выборке элементов по какому-либо признаку.
4.2 Найденные паттерны
Результат отфильтрованных паттернов, полученных с помощью алгоритма VMSP для различных баз данных приведён в ниже (Таблица 5).
Таблица 5
Результаты поиска паттернов с помощью алгоритма VMSP
|
База данных |
Паттерны, состоящие из разных элементов |
Количество паттернов (шт) |
Количество паттернов (%) |
|
IP-адрес отправителя |
Code Injection Input Validation Code Injection Other Other Code Injection Cryptographic Issues Other Other Cryptographic Issues Cryptographic Issues Other Cryptographic Issues Buffer Errors Code Injection |
631 591 721 708 596 779 601 |
0.0108 0.0101 0.0123 0.0121 0.0102 0.0133 0.0102 |
|
IP-адрес отправителя (в категорию добавлены порты отправителя) |
Code Injection (порт 445) Input Validation (порт 445) Code Injection (порт 445) Other (порт 445) Other (порт 80) Cryptographic Issues (порт 443) Cryptographic Issues (порт 443) Other (порт 80) Cryptographic Issues (порт 443) Other (порт 80) Cryptographic Issues (порт 443) |
647 626 618 745 728 |
0.011 0.0107 0.0105 0.0127 0.0124 |
|
IP-адрес отправителя, и IP-адрес получателя |
Code Injection Input Validation |
858 |
0.0101 |
|
IP-адрес отправителя, и IP-адрес получателя (в категорию добавлены порты отправителя) |
Code Injection (порт 445) Input Validation (порт 445) |
856 |
0.0101 |
В результате поиска паттернов можно сделать следующие выводы:
- В текущих данных нет часто встречающихся паттернов, но обнаружены некоторые паттерны, которые встречаются в 1 % данных. Малое количество паттернов может быть связано с большим разнообразием данных. Для улучшения результатов стоит попробовать взять больше событий, либо дополнительно отфильтровать данные.
- Найденные паттерны в основном состоят из Code Injection, Input Validation, Cryptographic Issues, Other и Buffer Errors, что в целом логично: именно они являются пятью наиболее часто встречающимися уязвимостями в исходных данных (Рисунок 2).
- В данных можно проследить атаки, начинающиеся с внедрения кода (Code Injection) и продолжающиеся ошибками валидации (Input Validation), что похоже на попытку несанкционированного входа в систему через ошибки системы. Сюда же можно отнести непонятные ошибки (Other), продолжающиеся внедрением кода.
- Также можно отметить, что в данных прослеживаются ошибки, связанные с криптографией (Cryptographic Issues), что вполне может быть связано с сертификатами, использующимися в компании.
5 Заключение
В данной работе коротко описаны методы поиска последовательностных паттернов и библиотеки SMPF, содержащей реализации алгоритмов этих методов. Приведено общее описание и особенности исследуемых данных.
Были опробованы различные алгоритмы поиска паттернов, приведено сравнение алгоритмов, в результате которого лучшим показал себя алгоритм VMSP. Показаны найденные паттерны и приведена авторская интерпретация полученных результатов.
В дальнейшем планируется исследовать алгоритмы поиска последовательностных правил (sequential rule mining) для поиска зависимостей в данных, также проверить корреляцию результатов с результатами поиска последовательностных паттернов.
Литература:
-
Data mining [Электронный ресурс] // Wikipedia: [сайт]. URL: https://ru.wikipedia.org/wiki/Data_mining (дата обращения: 13.04.2018).
Sequential pattern mining [Электронный ресурс] // Wikipedia: [сайт]. URL: https://en.wikipedia.org/wiki/Sequential_pattern_mining (дата обращения: 13.04.2018). - IBM Security QRadar. Log Event Extended Format (LEEF) URL: ftp://ftp.software.ibm.com/software/security/products/qradar/documents/iTeam_addendum/b_Leef_format_guide.pdf (дата обращения: 13.04.2018).
-
Межсетевое экранирование [Электронный ресурс] // Национальный Открытый Университет «ИНТУИТ»: [сайт]. URL: https://www.intuit.ru/studies/courses/20/20/lecture/631?page=4 (дата обращения: 13.04.2018).
Martin Husák J.K.E.B.H.P.Č. ARES '17 Proceedings of the 12th International Conference on Availability, Reliability and Security // On the Sequential Pattern and Rule Mining in the Analysis of Cyber Security Alerts. Italy. 2017. С. 1-20. -
SPMF An Open-Source Data Mining Library [Электронный ресурс] URL: http://www.philippe-fournier-viger.com/spmf/ (дата обращения: 13.04.2018).
Converting a Sequence Database to SPMF Format [Электронный ресурс] // SPMF: [сайт]. URL: https://www.philippe-fournier-viger.com/spmf/Converting_a_sequence_database_to_SPMF.php (дата обращения: 13.04.2018). - Vulnerabilities [Электронный ресурс] // NATIONAL VULNERABILITY DATABASE: [сайт]. URL: https://nvd.nist.gov/vuln/categories (дата обращения: 14.04.2018).
- SecAlertSeqMining [Электронный ресурс] // Github: [сайт]. URL: https://github.com/CSIRT-MU/SecAlertSeqMining (дата обращения: 14.04.2018).
