





Развитие интернета наряду с множеством положительных перемен в жизни людей увеличило угрозы вредоносных атак, вторжений в корпоративную сеть, краж конфиденциальной информации. Одним из способов минимизировать данные риски является аутентификация пользователей по клавиатурному почерку. В данной работе мы рассмотрим основные тенденции развития методов распознавания клавиатурного почерка, основанных на исследовании временных характеристик.
Ключевые слова: клавиатурный почерк, биометрическая аутентификация личности, временные характеристики, статистические методы оценки
Keywords: typing dynamics, biometric person authentication, time characteristics, statistical methods of evaluation
Идея использовать клавиатурный почерк для аутентификации личности не нова. Известно, что в годы Второй мировой войны спецслужбы разных стран учитывали «почерк радиста» при оценке достоверности источника полученных разведданных. Компьютеризация, стартовавшая в конце 70-х годов прошлого века, привела к началу систематических исследований в данном направлении. В 1979 году специалисты SRI International (до этого — Stanford Research Institute) представили чип со встроенным алгоритмом распознавания клавиатурного почерка. В 1984 году Национальное бюро стандартов США признало технологию эффективной на 98 %.
- Эффективность клавиатурного почерка как инструмента аутентификации
Клавиатурный почерк — это поведенческая биометрическая характеристика, состоящая из паттернов ритма и динамики, характерных для данного оператора при наборе текста. Клавиатурный почерк описывается следующими параметрами:
– скорость ввода — отношение количества введенных символов ко времени набора;
– динамика ввода — отрезки времени между нажатиями клавиш и их удержанием;
– частота возникновения ошибок при вводе;
– характерное использование клавиш — например, какие функциональные клавиши нажимает оператор при вводе заглавных букв.
Эффективность аутентификации по клавиатурному почерку, как и любого другого биометрического метода, определяется с помощью трех основных критериев:
– FAR (False Acceptance Rate) — процентный порог, определяющий вероятность того, что один человек может быть принят за другого (коэффициент ложного доступа). FAR также называют «ошибкой 2 рода»;
– FRR (False Rejection Rate) — вероятность того, что человек может быть не распознан системой (коэффициент ложного отказа в доступе). FRR также называют «ошибкой 1 рода»;
– CER (Crossover Error Rate) — точка, в которой калибровка системы приводит к равенству FAR = FRR.
На рис.1 показана диаграмма, характеризующая эффективность аутентификации по клавиатурному почерку в сравнении с другими методами биометрии: распознаванием по отпечаткам пальцев или по чертам лица — физическая биометрия, и еще одним методом поведенческой биометрии — распознаванием по речи.
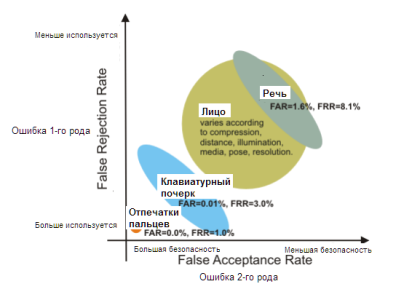
Рис. 1. Ошибки 1-го и 2-го рода при использовании разных методов биометрии [1]
Мы видим, что распознавание по клавиатурному почерку имеет хорошие показатели эффективности и уступает только аутентификации по отпечаткам пальцев. Вместе с тем, методы поведенческой биометрии могут быть «подогнаны» под конкретную задачу за счет компромисса между большей используемостью и большей безопасностью [5]. Поэтому FAR и FRR для клавиатурного почерка являются переменными величинами даже в рамках одного и того же алгоритма. Соответственно, в большем диапазоне меняется и величина CER.
Использование клавиатурного почерка для аутентификации личности имеет ряд несомненных преимуществ:
– алгоритмы относительно просты и могут быть реализованы как в виде ПО, так и прошиты в чипе;
– относительная дешевизна: реализация алгоритма не требует больших вложений, из «железа» фактически используется только клавиатура;
– скрытость использования, например, злоумышленник может и не подозревать о такой возможности;
– относительно высокая степень эффективности.
Однако, недостатки данного метода также очевидны:
– обязательный этап обучения приложения;
– при замене клавиатуры, скорее всего, понадобится переобучение;
– при изменении физического состояния оператора (болезнь, травма), он просто не сможет войти в систему.
- Данные для анализа ввода склавиатуры
Анализ клавиатурного почерка, наверное, самый дешевый метод аутентификации по используемому «железу»: нам необходима только клавиатура, которая и так представлена в любой конфигурации компьютера, ноутбука, мобильных устройств.
Конечно, каждый вид клавиатуры будет отличаться по ряду характеристик:
– Форма (прямоугольная, изогнутая, эргономическая);
– Необходимая сила нажима на клавишу;
– Расположение клавиш (AZERTY, QWERTY,...).
На рис. 2. представлено дерево различных топологий клавиатур в современных устройствах.
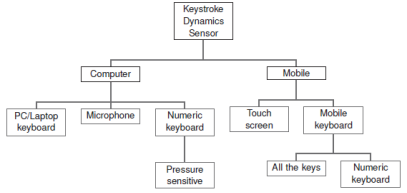
Рис. 2. Дерево различных топологий клавиатур по Дж. Янгу [14, c.164]
Биометрические данные о клавиатурном почерке — это список хронологически упорядоченных событий, содержащий следующую информацию:
– События, которые генерируются при работе с клавиатурой. Различают два вида событий: нажатие клавиш и их отпускание.
– Код клавиш. Код клавиши более интересен, чем значение символа, поскольку предоставляет дополнительную информацию о местонахождении клавиши на клавиатуре и позволяет дифференцировать различные ключи, что можно использовать при разработке приложений. Код клавиши зависит от платформы и используемого языка.
– Временные характеристики, соответствующие времени длительности событий.
Эффективность аутентификации существенно зависит от выбранного набора характеристик. В простейших случаях — и довольно часто — используются только лишь два основных параметра: длительность и задержка.
- Статистический подход кклассификации иидентификации по клавиатурному почерку
Задача распознавания — принадлежит ли данный образец набора текста конкретному человеку — решается либо путем перебора большой базы данных, либо с помощью сравнения с неким шаблоном аутентификации.
Как правило, биометрические данные нормализуются, учитывая, что временные характеристики распределены по логарифмически нормальному закону [14, c.168]:
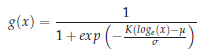 (1)
(1)
В своей классической работе Джойс и Гупта [2] предложили использовать вектор средних характеристик почерка оператора M = {Musername, Mpassword, Mfirstname, Mlastname}. Верификация заключается в сравнении тестовой подписи Т (полученной во время входа в систему) и М по величине отклонения, равной норме разницы L1 = ||M — T||. Положительное решение принимается в случае, если разница не превышает принятое пороговое значение. Среднее значение и стандартное отклонение нормы ||M-Si||, где Si — одна из восьми эталонных подписей, используется для определения порогового значения для допустимой разницы между Т и М.
Хотя данные по верификации были обнадеживающими, Джойс и Гупта использовали методику замещения, при которой распределение эталонного множества обязательно является репрезентативным для обучающего множества. Использование нескольких множеств данных, полученных в разное время, было бы более надежным.
Исследование классификаторов, основанных на данных, полученных от пользователей в разное время, исследовано в работе Монроуза [5]. Профайлы пользователей были представлены как N-мерные вектора характеристик, данные были разделены на обучающие и эталонные множества. Для распознавания использовался следующие классификаторы:
– Эвклидово расстояние между двумя N-мерными векторами U и R
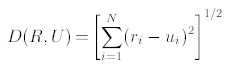 (2)
(2)
Для U из тестового множества проводился перебор по величинам D(Rj, U), j = 1,…m — где m — количество эталонных векторов (профайлов) в базе данных. В результате выбирался профайл с минимальным эвклидовым расстоянием к U.
– Невзвешенная вероятность: пусть U и R — N-мерные вектора, определенные выше.
Каждая компонента векторов является квадрупольной и включает в себя набор ![]() , состоящий из средней величины, стандартного отклонения, частоты события и значения для i-ой характеристики. Допустим, что каждая характеристика пользователя распределена нормально, тогда баллы в пользу профайла R при введенном U определяются как
, состоящий из средней величины, стандартного отклонения, частоты события и значения для i-ой характеристики. Допустим, что каждая характеристика пользователя распределена нормально, тогда баллы в пользу профайла R при введенном U определяются как
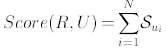 (3)
(3)
где
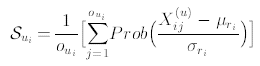 (4)
(4)
![]() — j-ое появление i-ой характеристики в U.
— j-ое появление i-ой характеристики в U.
Другими словами, баллы для каждого ui зависят от вероятности наблюдения величины ui в профайле R при средней (μri) и стандартном отклонении (σri) для данной характеристики в R. Большую вероятность имеют значения ui, которые находятся ближе к μri, меньшую — те, что дальше. Вектор U тогда ассоциируется с ближайшим соседом в базе данных, т. е. с оператором, для которого вектор характеристик будет максимальным.
– Взвешенная вероятность: некоторые характеристики являются более надежными
в сравнении с другими просто потому, что они представлены в большем количестве профайлов или имеют относительно большую частоту использования: например, er, th, reванглийском языке получат большие веса, чем qu или ts. Таким образом, можно ввести весовые множители, и баллы в пользу профайла R при введенном U будут рассчитываться как:
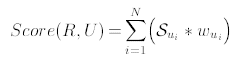 (5)
(5)
где вес характеристики ui определяется как соотношение частоты её появления к частоте появления всех характеристик в U. Характеристики с большим весом рассматриваются как более надежные. Допустим, что каждая характеристика пользователя распределена нормально, тогда баллы в пользу профайла R при введенном U определяются максимальными баллами и ближайшим вектором характеристик.
Монроуз обращает внимание на тот факт, что распознавание почерка по произвольному тексту является более сложной задачей в сравнении с распознаванием по фиксированному набору символов [5]. Проблемы при анализе произвольно введенного текста связаны с большим разнообразием физического и эмоционального состояния оператора, дополнительными неконтролируемыми внешними факторами.
При решении задачи распознавания клавиатурного почерка хорошо зарекомендовали себя байесовские классификаторы [6]. При этом распределение характеристик в векторе ввода считается Гауссовым, и U ассоциируется с вектором пользователя, который максимизирует вероятность R. Классификатор определяется следующим образом.
– Пусть xi — вектор характеристик, σi — вектор межклассовых дисперсий, wi — весовой вектор. Тогда расстояние между двумя векторами характеристик имеет вид
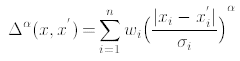 (6)
(6)
Вектора характеристик определяются на основе факторного анализа, целью которого является представление минимальной размерности, сохраняющее корреляцию между характеристиками. Существующая база данных разделяется на подклассы, члены которых подобны с точки зрения ритма набора и/или других временных факторов, при этом члены различных классов заметно отличаются по тем же факторам. Например, члены класса i связаны с индивидуальными особенностями набора символов S = {th, ate, st, ion}, в то время как члены класса j определяют набор T = {ere, on, wy}. Результат факторного анализа — иерархическая система кластеров, на основе которой идентифицируется пользователь.
Величина α в (6) подбирается для получения большей жесткости оценок: эффект сети лучше работает при α ближе к 1, чем к 2, что связано с распределением Гаусса.
Эффективность распознавания с байесовскими классификаторами достигает 92,14 %. Дополнительного улучшения на 5 % можно добиться при вводе весовых коэффициентов [5].
Литература:
- Checco John C. Keystroke Dynamics And Corporate Security // http://www.checcoservices.com/publications/2003_Keystroke_Biometrics_Intro.pdf
- Joyce R., Gupta G. Identity Authentication Based on Keystroke Latencies. — http://www.cs.cmu.edu/~maxion/courses/JoyceGupta90.pdf
- Loy C. C., Lim C. P., Lai W. K. Pressure-Based Typing Biometrics User Authentication Using the Fuzzy ARTMAP Neural Network. — http://www.eecs.qmul.ac.uk/~ccloy/files/iconip_2005.pdf
- Meloun M., Militky J. Statistical Data Analysis: A Practical Guide. — Woodhead Publishing, 2011. — 800 p.
- Monrose Fabian. Keystroke Dynamics as a Biometric for Authentication. — http://avirubin.com/fgcs.pdf
- Roth J., Liu X., Ross A.. Biometric Authentication via Keystroke Sound. — http://www.cse.msu.edu/~liuxm/publication/Roth_Liu_Ross_Metaxas_ICB2013.pdf
- Scott M. L. et al. Continuous Identity Verification through Keyboard Biometrics. — https://sa.rochester.edu/jur/issues/fall2005/ordal.pdf
